
Showing posts with label cluster. Show all posts
Showing posts with label cluster. Show all posts
Saturday, April 22, 2017
R: Utilizing multiple CPUs
R is a great piece of software to perform statistical analyses. Computing power can however be a limitation. R by default uses only a single CPU. In almost every machine, multiple CPUs are present, so why not utilize them?

Sunday, May 19, 2013
How to deal with services that don't support concurrency? Offer requests one at a time.
When developing service orchestrations using Oracle SOA Suite, an often encountered problem is dealing with unreliable services. This can be services which cannot handle multiple simultaneous requests (don't support concurrency) or don't have an 100% availability (usually due to nightly batches or scheduled maintenance). One way to work with these services is having a good error handling or retry mechanism in place. For example, I've previously described a fault handling mechanism based on using Advanced Queues (AQ); http://javaoraclesoa.blogspot.nl/2012/06/exception-handling-fault-management-and.html. Using this mechanism, you can maintain the order of processing for messages and retry faulted messages. It would however be better if we can avoid faults. In case a service does not support concurrency (because of for example platform limitations or statefulness), messages will have to be offered one at a time.
If the service has a quick response time, you can make a process picking up messages from a AQ, synchronous and thus have only one running process at a time. This has been described at; http://mazanatti.info/index.php?/archives/81-SOA-Suite-11g-truly-singleton-with-AQ-Adapter.html. It's a recommended read.
In this blog post I'll describe a mechanism which can be used if a synchronous solution would not suffice, for example in long running processes. The purpose of this blog post is to illustrate a mechanism and it's components. It should not be used as-is in a production environment but tweaked to business requirements.
Implementation
I'll describe a database based mechanism which consists of several components;
- A database table holding process 'state'. In this example, CREATED, ENQUEUED, RUNNING, DONE
- A DBMS_SCHEDULER job which polls for changes. In my experience this is more stable then using the DbAdapter to do the same.
- A priority AQ to offer messages to BPEL in a specific order and allow loose coupling/flexibility/error handling mechanisms. In my experience this is very reliable.
- A BPEL process consuming AQ messages and calling the service which doesn't support concurrency. There should be only one running instance of this process at a time.

I've created a process state table which holds the process states and provides state history. I've also created a view on this table which only displays the current state. There is a column in the table PROC_NAME. This corresponds to the subscriber used in the BPEL process.
A database job polls for records every minute with state CREATED. If found and no other processes are in state ENQUEUED or RUNNING, a new message is enqueued. I've split the states ENQUEUED and RUNNING to be able to identify which messages have been picked up by the BPEL process and which haven't. There should only be one process in state RUNNING at a time.
I've created a simple HelloWorld BPEL process. This process polls for messages on the AQ. It picks up the message and informs the database that it has picked up a message (set the state to RUNNING). Next I've stubbed calling a service with a wait of one minute. After the period is over, the state is set to DONE. The process looks as followed;




AQ in a clustered environment
In a clustered environment you have to mind that in an 11.2 database, AQ messages can be picked up twice from the same queue under load. Since this would break the mechanism, I suggest taking the below described workaround.
Bug: 13729601
Added: 20-February-2012
Platform: All
The dequeuer returns the same message in multiple threads in high concurrency environments when Oracle database 11.2 is used. This means that some messages are dequeued more than once. For example, in Oracle SOA Suite, if Service 1 suddenly raises a large number of business events that are subscribed to by Service 2, duplicate instances of Service 2 triggered by the same event may be seen in an intermittent fashion. The same behavior is not observed with a 10.2.0.5 database or in an 11.2 database with event10852 level 16384 set to disable the 11.2 dequeue optimizations.
Workaround: Perform the following steps:
Log in to the 11.2 database:
CONNECT /AS SYSDBA
Specify the following SQL command in SQL*Plus to disable the 11.2 dequeue optimizations:
SQL> alter system set event='10852 trace name context forever,
level 16384'scope=spfile;
Considerations
The mechanism described can be used to avoid parallel execution of processes. Even when the processes are long running and synchronous execution is not an option.
Polling
The mechanism contains polling components; the DBMS_SCHEDULER job and the AqAdapter. This has two major drawbacks;
- it will cause load even when the system is idle
- it allows a period between finishing of a process and starting of the next process
You could consider starting the BPEL process actively from the database (thus avoiding polling) by using for example UTL_DBWS (see for example http://orasoa.blogspot.nl/2006/11/calling-bpel-process-with-utldbws.html). This however requires that the URL of the BPEL process is known in the database and that the ACL (Access Control List) is configured correctly. Also error handling should be reconsidered. The overhead of polling is minor. If a delay of 1 minute + default AqAdapter polling frequency is acceptable, a solution based on the described mechanism can be considered. Also, the DBMS_SCHEDULER job polling frequency can be reduced and the AqAdapter polling behavior can be tweaked to reduce the lost time between polls.
Chaining
Ending the process with a polling action -> initiation of the next message is not advisable since it raises several new questions;
- what to do if there are no messages waiting? having a polling mechanism together with this mechanism might break the 'only one process is running at the same time'-rule
- what to do in case of errors -> when the chain is broken
Retiring/activating
I've tried a mechanism which would retire a process at the start and then reactivate it after completion. This would disallow more then one process to be running at the same time. This appeared not to be a solid mechanism. Retiring and activating a process takes time in which new messages could be picked up. Also using the Oracle SOA API during process execution adversely effects performance.
Efficiently determining the current state
I've not tested this solution with large number of processes. I think in that case I should reconsider on how to keep a process history and get to the current state efficiently in a polling run. Most likely I'd use two tables. One for the current state which I would update and another separate table for the history which I would fill with PL/SQL triggers on the current state table.
Download
You can download the BPEL process here; https://dl.dropboxusercontent.com/u/6693935/blog/HelloWorldAQProcState.zip
The databasecode can be downloaded here (you might want to neatify it if for example you like CDM);
https://dl.dropboxusercontent.com/u/6693935/blog/processstate.txt
If the service has a quick response time, you can make a process picking up messages from a AQ, synchronous and thus have only one running process at a time. This has been described at; http://mazanatti.info/index.php?/archives/81-SOA-Suite-11g-truly-singleton-with-AQ-Adapter.html. It's a recommended read.
In this blog post I'll describe a mechanism which can be used if a synchronous solution would not suffice, for example in long running processes. The purpose of this blog post is to illustrate a mechanism and it's components. It should not be used as-is in a production environment but tweaked to business requirements.
Implementation
I'll describe a database based mechanism which consists of several components;
- A database table holding process 'state'. In this example, CREATED, ENQUEUED, RUNNING, DONE
- A DBMS_SCHEDULER job which polls for changes. In my experience this is more stable then using the DbAdapter to do the same.
- A priority AQ to offer messages to BPEL in a specific order and allow loose coupling/flexibility/error handling mechanisms. In my experience this is very reliable.
- A BPEL process consuming AQ messages and calling the service which doesn't support concurrency. There should be only one running instance of this process at a time.

I've created a process state table which holds the process states and provides state history. I've also created a view on this table which only displays the current state. There is a column in the table PROC_NAME. This corresponds to the subscriber used in the BPEL process.
A database job polls for records every minute with state CREATED. If found and no other processes are in state ENQUEUED or RUNNING, a new message is enqueued. I've split the states ENQUEUED and RUNNING to be able to identify which messages have been picked up by the BPEL process and which haven't. There should only be one process in state RUNNING at a time.
I've created a simple HelloWorld BPEL process. This process polls for messages on the AQ. It picks up the message and informs the database that it has picked up a message (set the state to RUNNING). Next I've stubbed calling a service with a wait of one minute. After the period is over, the state is set to DONE. The process looks as followed;

At the end of this post you can download the code. To run the example however, the database needs to have a user TESTUSER with the correct grants to alllow queueing/dequeueing (see supplied script). Also in Weblogic server, there needs to be a JDBC datasource configured and a connection factory (eis/AQ/testuser) defined in the AqAdapter. You can find an example for configuring the DbAdapter at http://kiransaravi.blogspot.nl/2012/08/configuring-dbadapter-its-datasource.html. Configuration for the AqAdapter is very similar.
Running the example
First you need to create the table, trigger, AQ, package, DBMS_SCHEDULER job. This can be done by executing the supplied script.
To start testing the mechanism you can execute the following;
begin
insert into ms_process(proc_name,proc_comment) values('HELLOWORLD','Added new record for test 1');
insert into ms_process(proc_name,proc_comment) values('HELLOWORLD','Added new record for test 2');
insert into ms_process(proc_name,proc_comment) values('HELLOWORLD','Added new record for test 3');
commit;
end;
This will insert 3 records in the process table. These messages will be picked up in order. For implementations in larger applications I recommend using the PROC_SEQ field in the process table to obtain required information for processing.
After a couple of minutes, you can see the following in the process state table;

As you can see, the messages were created at approximately the same time. The messages are picked up in order of insertion (based on ProcessId). Also as can be seen from the table, when a process is running (the period between state RUNNING and DONE), no other processes are running; there is no overlap in time.
After processing, the process view indicates the latest process state for every process. All processes are done.
In the Enterprise Manager, three processes have been executed and completed.
In a clustered environment you have to mind that in an 11.2 database, AQ messages can be picked up twice from the same queue under load. Since this would break the mechanism, I suggest taking the below described workaround.
Bug: 13729601
Added: 20-February-2012
Platform: All
The dequeuer returns the same message in multiple threads in high concurrency environments when Oracle database 11.2 is used. This means that some messages are dequeued more than once. For example, in Oracle SOA Suite, if Service 1 suddenly raises a large number of business events that are subscribed to by Service 2, duplicate instances of Service 2 triggered by the same event may be seen in an intermittent fashion. The same behavior is not observed with a 10.2.0.5 database or in an 11.2 database with event10852 level 16384 set to disable the 11.2 dequeue optimizations.
Workaround: Perform the following steps:
Log in to the 11.2 database:
CONNECT /AS SYSDBA
Specify the following SQL command in SQL*Plus to disable the 11.2 dequeue optimizations:
SQL> alter system set event='10852 trace name context forever,
level 16384'scope=spfile;
Considerations
The mechanism described can be used to avoid parallel execution of processes. Even when the processes are long running and synchronous execution is not an option.
Polling
The mechanism contains polling components; the DBMS_SCHEDULER job and the AqAdapter. This has two major drawbacks;
- it will cause load even when the system is idle
- it allows a period between finishing of a process and starting of the next process
You could consider starting the BPEL process actively from the database (thus avoiding polling) by using for example UTL_DBWS (see for example http://orasoa.blogspot.nl/2006/11/calling-bpel-process-with-utldbws.html). This however requires that the URL of the BPEL process is known in the database and that the ACL (Access Control List) is configured correctly. Also error handling should be reconsidered. The overhead of polling is minor. If a delay of 1 minute + default AqAdapter polling frequency is acceptable, a solution based on the described mechanism can be considered. Also, the DBMS_SCHEDULER job polling frequency can be reduced and the AqAdapter polling behavior can be tweaked to reduce the lost time between polls.
Chaining
Ending the process with a polling action -> initiation of the next message is not advisable since it raises several new questions;
- what to do if there are no messages waiting? having a polling mechanism together with this mechanism might break the 'only one process is running at the same time'-rule
- what to do in case of errors -> when the chain is broken
Retiring/activating
I've tried a mechanism which would retire a process at the start and then reactivate it after completion. This would disallow more then one process to be running at the same time. This appeared not to be a solid mechanism. Retiring and activating a process takes time in which new messages could be picked up. Also using the Oracle SOA API during process execution adversely effects performance.
Efficiently determining the current state
I've not tested this solution with large number of processes. I think in that case I should reconsider on how to keep a process history and get to the current state efficiently in a polling run. Most likely I'd use two tables. One for the current state which I would update and another separate table for the history which I would fill with PL/SQL triggers on the current state table.
Download
You can download the BPEL process here; https://dl.dropboxusercontent.com/u/6693935/blog/HelloWorldAQProcState.zip
The databasecode can be downloaded here (you might want to neatify it if for example you like CDM);
https://dl.dropboxusercontent.com/u/6693935/blog/processstate.txt
Friday, November 9, 2012
SOA Suite Cluster deployments and loadbalancers
When using Ant tasks to deploy to an Oracle SOA Suite cluster certain issues can occur. You deploy usually to one Managed Server and the cluster will propagate the deployment to the other nodes in the cluster. Often before this happens, the Ant script continues with the deployment of a next process (usually deployment is scripted this way. see for example http://biemond.blogspot.nl/2009/09/deploy-soa-suite-11g-composite.html). When resources are accessed using a loadbalancer, the loadbalancer can refer for certain resources to a managed server (node in the cluster) where the process is not deployed yet. This can cause deployment issues. You can not work around this by separately deploying to the nodes of the cluster. See http://www.oracle.com/technetwork/topics/soa/oracle-soa-suite-ha-faq-1-131459.pdf section 3.. Usually re-executing the deployment script is a workaround since the process is then usually already present on both cluster nodes.
Also when starting a managed server, a similar problem can arise. Take for example a cluster which consists of two managed servers. The first server is shutdown and started (changing certain settings requires a restart of the server) and when the first server has state 'Running' the second server is shutdown and started, the first server can get into problems loading composites since the loadbalancer might refer to resources on the second server when those resources are not loaded yet. Inconsistencies can arise between the two nodes; for example processes which are valid on the first node and invalid on the second.
Also see http://docs.oracle.com/cd/E28271_01/admin.1111/e10226/soainfra_config.htm#BHCCIJAE for this behavior; After the SOA Infrastructure is started, it may not be completely initialized to administer incoming requests until all deployed composites are loaded.I have not found a way to change this behavior. What you would want is that the loadbalancer does not refer to a server when it is not completely initialized.
The description below is the path I took to eventually find the best solution to both described issues above. If you're just interested in the solution, look at the bottom of this post and skip the 'Failed experiments' section. BEWARE: some users have reported stuck threads when using this code so it might require some work. If you're interested in a bit of background and would like to avoid certain pitfalls, I'd suggest reading the entire post. The issue is that the loadbalancer should be able to get an accurate reading concerning the availability of a server.
How to deal with the loadbalancer
If you have a smart loadbalancer, you can configure what it uses as probe to determine if a server is running. The Weblogic Server state is insufficient for that when running Oracle SOA Suite as described above.
Creating an efficient probe for the loadbalancer is not as straightforward as it might seem. The loadbalancer looks at individual nodes to determine if it is running. You can create a probe to determine loaded processes. This is however insufficient since you will not be able to tackle the problem of deployment to one node and at a later time to the other node; both nodes will show lists of loaded processes, however one node will show less processes.
The Locator class (http://docs.oracle.com/cd/E21043_01/apirefs.1111/e10659/oracle/soa/management/facade/Locator.html) can be used to obtain a list of composites. A Locator instance can be created from within a deployed composite or by using JNDI connection properties. Both are however server instance specific and you are not able to compare the two nodes.
It is possible to obtain the managed server instances from the admin server by using MBeans. See; http://middlewaremagic.com/weblogic/?p=913. I've adapted this to allow remote connections for local testing and local connections from BPEL. When calling the code from BPEL I've used a Java embedding activity. Required libraries (JDeveloper) for compilation are;
- Weblogic 10.3 remote client
- SOA Runtime
- SOA Designtime
- BPEL Runtime
Failed experiments
'Failed experiments' would suggest I tried to achieve certain functionality but couldn't get the code to perform what I wanted. In this case the code produced does what I wanted to achieve, however my way of thinking was wrong. The below code examples look at the server state based on loaded composites and comparing managed servers. This is not an accurate measure of server availability and is not usuable by a loadbalancer. The code can however be used in other usecases. That's why I included it in this post.
Remote client for local testing
The getServerUpRemote method in the code below returns true or false. It asks the AdminServer for all Managed Servers which are up. It then goes to the managed servers and asks for the Composites running in those servers and compares the lists. True means everything is ok. False means that one or more managed servers in the cluster have differences in loaded composites, states or versions.
In order to get the managed servers I first access the AdminServer by using JMX in order to obtain a MBeanServerConnection. This connection can be used to determine the Managed Servers. Next, I use JNDI to find the Locator class on the Managed Servers in order to get the list of Composites.
See for the code; https://dl.dropbox.com/u/6693935/blog/remoteconnections.txt
Local connection from deployed composite/servlet
Of course the loadbalancer would not be able to access my local JDeveloper installation so I wanted to deploy the code to run on the server. Also I wanted to avoid having to use server credentials. I first tried wrapping the code in a servlet and deploying the servlet on the AdminServer. This was not succesful since I had difficulties accessing resources on the Managed Servers without providing credentials. I encountered for example the following error;
java.security.PrivilegedActionException: javax.naming.NameNotFoundException: Unable to resolve 'FacadeFinderBean'. Resolved ''; remaining name 'FacadeFinderBean'
When I deployed the code in a BPEL process, there would be difficulties to access AdminServer resources and resources on other Managed Servers in the cluster.
To avoid above issues, I split the code in two parts. A servlet running on the AdminServer and a BPEL process running on the Managed Servers. The servlet would be able to provide the managed servers and the BPEL processes would be able to provide information on their runtime. The servlet could call the processes on the managed servers and compare the results.
The below code also illustrates how to call a webservice from Java and deal with the result without the requirement to generate webservice specific Java proxy classes. I used http://www.coderanch.com/t/206857/sockets/java/Http-Post-XML-example as an example.
See for the code;
https://dl.dropbox.com/u/6693935/blog/localconnections.txt
This however was still insufficient because I would need to ask the AdminServer via the servlet if the Managed Servers are up and all processes are in the same state. A loadbalancer would be unable to determine which node is up, only if the state as a whole is safe. This total state can be used during an installation to check if it is already time to deploy the next process or if a wait is required to propagate the deployment to the other nodes. This does not fix the node start-up issues. If I proxy the AdminServer servlet on the managed servers, during deployment, both managed servers would seem to be down if the responses of loaded processes are not equal. This can cause the loadbalancer to not send requests to a server which is actually up. When I return the Ok status for the managed server which has most processes loaded, I still am not sure that server is fully started.
The right path
The magic bean I couldn't access
What I needed to solve the issues in the introduction is an MBean on the Managed Servers indicating is the Managed Server has loaded all processes or is still 'initializing'.

Eventually I found this MBean; oracle.soa.config:Application=soa-infra,j2eeType=CompositeLifecycleConfig,name=soa-infra
It can be accessed using an MBeanServerConnection found by using JMX looking for weblogic.management.mbeanservers.runtime. I also used http://www.albinsblog.com/2011/10/oracle-soa-11g-getting-default-version.html#.UJvMYoaJXsc for a bit of the JMX part.
This is illustrated in the following code. To get this to compile I used the following libraries;
- Weblogicv 10.3 remote client
- Servlet runtime
- wljmxclient.jar and wlclient.jar (wlserver_10.3/server/lib). these are required for the t3 protocol used when connecting from a client (code in public static void main). Else you will encounter 'java.net.MalformedURLException: Unsupported protocol: t3' (see; http://code.google.com/p/wlsagent/issues/detail?id=3)
The below code illustrates how to get to the MBean you want. I followed the following procedure to determine how to get there;
- browsed the MBeans using Fusion Middleware Control to find the correct MBean
- used the post mentioned before to get to the correct MBeanServerConnection (this differs from the MBeanServerConnection used in the 2 code samples earlier in this post!)
- illustrated in comments at the end of the code; used the following to obtain the correct ObjectName; Set<ObjectName> myObjs = myCon.queryNames(new ObjectName("*:j2eeType=CompositeLifecycleConfig,*"), null);
- determined the class of the attribute (in this case SOAPlatformStatus) I wanted. it appeared to be a javax.management.openmbean.CompositeDataSupport. I did this like; connection.getAttribute(getSOAInfraServiceName(),"SOAPlatformStatus").getClass().toString()
- get the value from the obtained object by using the key ('isReady' in this case)
package ms.testapp.soa.utils;
import java.io.IOException;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.net.MalformedURLException;
import java.util.Hashtable;
import javax.management.MBeanServer;
import javax.management.MBeanServerConnection;
import javax.management.MalformedObjectNameException;
import javax.management.ObjectName;
import javax.management.remote.JMXConnector;
import javax.management.remote.JMXConnectorFactory;
import javax.management.remote.JMXServiceURL;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class DetermineServerStatus extends HttpServlet {
public DetermineServerStatus() {
super();
}
private static MBeanServerConnection getRemoteConnection(String hostname,
String portString,
String username,
String password) throws IOException,
MalformedURLException {
JMXConnector connector = null;
MBeanServerConnection connection = null;
//System.out.println("ServerDetails---Started in initConnection");
String protocol = "t3";
Integer portInteger = Integer.valueOf(portString);
int port = portInteger.intValue();
String jndiroot = "/jndi/";
String mserver = "weblogic.management.mbeanservers.runtime";
//String mserver = "weblogic.management.mbeanservers.domainruntime";
JMXServiceURL serviceURL =
new JMXServiceURL(protocol, hostname, port, jndiroot + mserver);
Hashtable h = new Hashtable();
h.put(Context.SECURITY_PRINCIPAL, username);
h.put(Context.SECURITY_CREDENTIALS, password);
h.put(JMXConnectorFactory.PROTOCOL_PROVIDER_PACKAGES,
"weblogic.management.remote");
connector = JMXConnectorFactory.connect(serviceURL, h);
connection = connector.getMBeanServerConnection();
return connection;
}
private static MBeanServerConnection getLocalConnection() throws NamingException {
InitialContext ctx = new InitialContext();
MBeanServer server = (MBeanServer)ctx.lookup("java:comp/env/jmx/runtime");
//(MBeanServer)ctx.lookup("java:comp/env/jmx/domainRuntime");
return server;
}
private static ObjectName getSOAInfraServiceName() {
ObjectName service = null;
try {
service =
new ObjectName("oracle.soa.config:Application=soa-infra,j2eeType=CompositeLifecycleConfig,name=soa-infra");
} catch (MalformedObjectNameException e) {
throw new AssertionError(e.getMessage());
}
return service;
}
private static javax.management.openmbean.CompositeDataSupport getSOAPlatformStatusObjects(MBeanServerConnection connection) throws Exception {
//System.out.println(connection.getAttribute(getSOAInfraServiceName(),
// "SOAPlatformStatus").getClass().toString());
return (javax.management.openmbean.CompositeDataSupport)connection.getAttribute(getSOAInfraServiceName(),
"SOAPlatformStatus");
}
private static String getSOAPlatformStatus(MBeanServerConnection connection) {
try {
return ((Boolean)getSOAPlatformStatusObjects(connection).get("isReady")).toString();
} catch (Exception e) {
//in case bean not accessible -> server not ready
return stackTraceToString(e);
}
}
private static String stackTraceToString(Throwable e) {
String retValue = null;
StringWriter sw = null;
PrintWriter pw = null;
try {
sw = new StringWriter();
pw = new PrintWriter(sw);
e.printStackTrace(pw);
retValue = sw.toString();
} finally {
try {
if (pw != null)
pw.close();
if (sw != null)
sw.close();
} catch (IOException ignore) {
//System.out.println(stackTraceToString(e));
}
}
return retValue;
}
public void doPost(HttpServletRequest request,
HttpServletResponse response) throws ServletException,
IOException {
doGet(request, response);
}
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException,
IOException {
PrintWriter out = response.getWriter();
try {
out.println(getServerStatusLocal());
} catch (Exception e) {
out.println(stackTraceToString(e));
}
}
public String getServerStatusLocal() {
MBeanServerConnection myCon;
try {
myCon = getLocalConnection();
} catch (NamingException e) {
//no MBean connection; server not ready
return stackTraceToString(e);
}
return getSOAPlatformStatus(myCon);
}
public static void main(String[] args) {
String host = "192.168.178.17";
String port = "7001";
String user = "weblogic";
String password = "xxx";
MBeanServerConnection myCon;
try {
myCon = getRemoteConnection(host, port, user, password);
//Set<ObjectName> myObjs = myCon.queryNames(new ObjectName("*:j2eeType=CompositeLifecycleConfig,*"), null);
//for (ObjectName myObj : myObjs) {
// System.out.println(myObj.getCanonicalName());
//}
System.out.println(getSOAPlatformStatus(myCon));
} catch (Exception e) {
System.out.println(stackTraceToString(e));
}
}
}
This servlet I could deploy to the managed servers to get the status. This however... failed because of;
javax.management.RuntimeMBeanException: java.lang.SecurityException: MBean attribute access denied.
MBean: oracle.soa.config:name=soa-infra,j2eeType=CompositeLifecycleConfig,Application=soa-infra
Getter for attribute SOAPlatformStatus
Detail: Access denied. Required roles: Admin, Operator, Monitor, executing subject: principals=[]
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.rethrow(DefaultMBeanServerInterceptor.java:856)
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.rethrowMaybeMBeanException(DefaultMBeanServerInterceptor.java:869)
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.getAttribute(DefaultMBeanServerInterceptor.java:670)
at com.sun.jmx.mbeanserver.JmxMBeanServer.getAttribute(JmxMBeanServer.java:638)
So I thought I could maybe deploy this as part of a BPEL process. When running in another context, these SecurityExceptions might not be raised. When refactoring the code and testing the BPEL process however I still got the same exception.
Accessing the MBean
I found; http://docs.oracle.com/cd/E11035_01/wls100/security/thin_client.html#wp1046345 and got back to my servlet code. Then I added a weblogic.xml deployment descriptor, a role to web.xml and a role mapping to weblogic.xml and it worked! The code can be downloaded from; https://dl.dropbox.com/u/6693935/blog/DetermineServerStatus.zip
The BPEL code is for reference purposes only. I haven't applied the role assignment to the BPEL code. The servlet has an additional benefit that it is more easily tweakable to the response wanted by the loadbalancer
Below a screenshot of the result when the server is fully started.

We performed the following test to confirm the expected behavior.
- first deploy the servlet to the managed servers in a cluster
- confirm the servlet output for the managed servers is true (by accessing them directly, not via a loadbalancer)
- shutdown one node and confirm the servlet cannot be accessed. confirm the other node still replies 'true'
- start the node and wait till it has state Running
- confirm the servlet output for that node is false and for the other node is true
- wait a while (until all processes are loaded)
- confirm that for both nodes the servlet output is true
Also when starting a managed server, a similar problem can arise. Take for example a cluster which consists of two managed servers. The first server is shutdown and started (changing certain settings requires a restart of the server) and when the first server has state 'Running' the second server is shutdown and started, the first server can get into problems loading composites since the loadbalancer might refer to resources on the second server when those resources are not loaded yet. Inconsistencies can arise between the two nodes; for example processes which are valid on the first node and invalid on the second.
Also see http://docs.oracle.com/cd/E28271_01/admin.1111/e10226/soainfra_config.htm#BHCCIJAE for this behavior; After the SOA Infrastructure is started, it may not be completely initialized to administer incoming requests until all deployed composites are loaded.I have not found a way to change this behavior. What you would want is that the loadbalancer does not refer to a server when it is not completely initialized.
The description below is the path I took to eventually find the best solution to both described issues above. If you're just interested in the solution, look at the bottom of this post and skip the 'Failed experiments' section. BEWARE: some users have reported stuck threads when using this code so it might require some work. If you're interested in a bit of background and would like to avoid certain pitfalls, I'd suggest reading the entire post. The issue is that the loadbalancer should be able to get an accurate reading concerning the availability of a server.
How to deal with the loadbalancer
If you have a smart loadbalancer, you can configure what it uses as probe to determine if a server is running. The Weblogic Server state is insufficient for that when running Oracle SOA Suite as described above.
Creating an efficient probe for the loadbalancer is not as straightforward as it might seem. The loadbalancer looks at individual nodes to determine if it is running. You can create a probe to determine loaded processes. This is however insufficient since you will not be able to tackle the problem of deployment to one node and at a later time to the other node; both nodes will show lists of loaded processes, however one node will show less processes.
The Locator class (http://docs.oracle.com/cd/E21043_01/apirefs.1111/e10659/oracle/soa/management/facade/Locator.html) can be used to obtain a list of composites. A Locator instance can be created from within a deployed composite or by using JNDI connection properties. Both are however server instance specific and you are not able to compare the two nodes.
It is possible to obtain the managed server instances from the admin server by using MBeans. See; http://middlewaremagic.com/weblogic/?p=913. I've adapted this to allow remote connections for local testing and local connections from BPEL. When calling the code from BPEL I've used a Java embedding activity. Required libraries (JDeveloper) for compilation are;
- Weblogic 10.3 remote client
- SOA Runtime
- SOA Designtime
- BPEL Runtime
Failed experiments
'Failed experiments' would suggest I tried to achieve certain functionality but couldn't get the code to perform what I wanted. In this case the code produced does what I wanted to achieve, however my way of thinking was wrong. The below code examples look at the server state based on loaded composites and comparing managed servers. This is not an accurate measure of server availability and is not usuable by a loadbalancer. The code can however be used in other usecases. That's why I included it in this post.
Remote client for local testing
The getServerUpRemote method in the code below returns true or false. It asks the AdminServer for all Managed Servers which are up. It then goes to the managed servers and asks for the Composites running in those servers and compares the lists. True means everything is ok. False means that one or more managed servers in the cluster have differences in loaded composites, states or versions.
In order to get the managed servers I first access the AdminServer by using JMX in order to obtain a MBeanServerConnection. This connection can be used to determine the Managed Servers. Next, I use JNDI to find the Locator class on the Managed Servers in order to get the list of Composites.
See for the code; https://dl.dropbox.com/u/6693935/blog/remoteconnections.txt
Local connection from deployed composite/servlet
Of course the loadbalancer would not be able to access my local JDeveloper installation so I wanted to deploy the code to run on the server. Also I wanted to avoid having to use server credentials. I first tried wrapping the code in a servlet and deploying the servlet on the AdminServer. This was not succesful since I had difficulties accessing resources on the Managed Servers without providing credentials. I encountered for example the following error;
java.security.PrivilegedActionException: javax.naming.NameNotFoundException: Unable to resolve 'FacadeFinderBean'. Resolved ''; remaining name 'FacadeFinderBean'
When I deployed the code in a BPEL process, there would be difficulties to access AdminServer resources and resources on other Managed Servers in the cluster.
To avoid above issues, I split the code in two parts. A servlet running on the AdminServer and a BPEL process running on the Managed Servers. The servlet would be able to provide the managed servers and the BPEL processes would be able to provide information on their runtime. The servlet could call the processes on the managed servers and compare the results.
The below code also illustrates how to call a webservice from Java and deal with the result without the requirement to generate webservice specific Java proxy classes. I used http://www.coderanch.com/t/206857/sockets/java/Http-Post-XML-example as an example.
See for the code;
https://dl.dropbox.com/u/6693935/blog/localconnections.txt
This however was still insufficient because I would need to ask the AdminServer via the servlet if the Managed Servers are up and all processes are in the same state. A loadbalancer would be unable to determine which node is up, only if the state as a whole is safe. This total state can be used during an installation to check if it is already time to deploy the next process or if a wait is required to propagate the deployment to the other nodes. This does not fix the node start-up issues. If I proxy the AdminServer servlet on the managed servers, during deployment, both managed servers would seem to be down if the responses of loaded processes are not equal. This can cause the loadbalancer to not send requests to a server which is actually up. When I return the Ok status for the managed server which has most processes loaded, I still am not sure that server is fully started.
The right path
The magic bean I couldn't access
What I needed to solve the issues in the introduction is an MBean on the Managed Servers indicating is the Managed Server has loaded all processes or is still 'initializing'.

Eventually I found this MBean; oracle.soa.config:Application=soa-infra,j2eeType=CompositeLifecycleConfig,name=soa-infra
It can be accessed using an MBeanServerConnection found by using JMX looking for weblogic.management.mbeanservers.runtime. I also used http://www.albinsblog.com/2011/10/oracle-soa-11g-getting-default-version.html#.UJvMYoaJXsc for a bit of the JMX part.
This is illustrated in the following code. To get this to compile I used the following libraries;
- Weblogicv 10.3 remote client
- Servlet runtime
- wljmxclient.jar and wlclient.jar (wlserver_10.3/server/lib). these are required for the t3 protocol used when connecting from a client (code in public static void main). Else you will encounter 'java.net.MalformedURLException: Unsupported protocol: t3' (see; http://code.google.com/p/wlsagent/issues/detail?id=3)
The below code illustrates how to get to the MBean you want. I followed the following procedure to determine how to get there;
- browsed the MBeans using Fusion Middleware Control to find the correct MBean
- used the post mentioned before to get to the correct MBeanServerConnection (this differs from the MBeanServerConnection used in the 2 code samples earlier in this post!)
- illustrated in comments at the end of the code; used the following to obtain the correct ObjectName; Set<ObjectName> myObjs = myCon.queryNames(new ObjectName("*:j2eeType=CompositeLifecycleConfig,*"), null);
- determined the class of the attribute (in this case SOAPlatformStatus) I wanted. it appeared to be a javax.management.openmbean.CompositeDataSupport. I did this like; connection.getAttribute(getSOAInfraServiceName(),"SOAPlatformStatus").getClass().toString()
- get the value from the obtained object by using the key ('isReady' in this case)
package ms.testapp.soa.utils;
import java.io.IOException;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.net.MalformedURLException;
import java.util.Hashtable;
import javax.management.MBeanServer;
import javax.management.MBeanServerConnection;
import javax.management.MalformedObjectNameException;
import javax.management.ObjectName;
import javax.management.remote.JMXConnector;
import javax.management.remote.JMXConnectorFactory;
import javax.management.remote.JMXServiceURL;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class DetermineServerStatus extends HttpServlet {
public DetermineServerStatus() {
super();
}
private static MBeanServerConnection getRemoteConnection(String hostname,
String portString,
String username,
String password) throws IOException,
MalformedURLException {
JMXConnector connector = null;
MBeanServerConnection connection = null;
//System.out.println("ServerDetails---Started in initConnection");
String protocol = "t3";
Integer portInteger = Integer.valueOf(portString);
int port = portInteger.intValue();
String jndiroot = "/jndi/";
String mserver = "weblogic.management.mbeanservers.runtime";
//String mserver = "weblogic.management.mbeanservers.domainruntime";
JMXServiceURL serviceURL =
new JMXServiceURL(protocol, hostname, port, jndiroot + mserver);
Hashtable h = new Hashtable();
h.put(Context.SECURITY_PRINCIPAL, username);
h.put(Context.SECURITY_CREDENTIALS, password);
h.put(JMXConnectorFactory.PROTOCOL_PROVIDER_PACKAGES,
"weblogic.management.remote");
connector = JMXConnectorFactory.connect(serviceURL, h);
connection = connector.getMBeanServerConnection();
return connection;
}
private static MBeanServerConnection getLocalConnection() throws NamingException {
InitialContext ctx = new InitialContext();
MBeanServer server = (MBeanServer)ctx.lookup("java:comp/env/jmx/runtime");
//(MBeanServer)ctx.lookup("java:comp/env/jmx/domainRuntime");
return server;
}
private static ObjectName getSOAInfraServiceName() {
ObjectName service = null;
try {
service =
new ObjectName("oracle.soa.config:Application=soa-infra,j2eeType=CompositeLifecycleConfig,name=soa-infra");
} catch (MalformedObjectNameException e) {
throw new AssertionError(e.getMessage());
}
return service;
}
private static javax.management.openmbean.CompositeDataSupport getSOAPlatformStatusObjects(MBeanServerConnection connection) throws Exception {
//System.out.println(connection.getAttribute(getSOAInfraServiceName(),
// "SOAPlatformStatus").getClass().toString());
return (javax.management.openmbean.CompositeDataSupport)connection.getAttribute(getSOAInfraServiceName(),
"SOAPlatformStatus");
}
private static String getSOAPlatformStatus(MBeanServerConnection connection) {
try {
return ((Boolean)getSOAPlatformStatusObjects(connection).get("isReady")).toString();
} catch (Exception e) {
//in case bean not accessible -> server not ready
return stackTraceToString(e);
}
}
private static String stackTraceToString(Throwable e) {
String retValue = null;
StringWriter sw = null;
PrintWriter pw = null;
try {
sw = new StringWriter();
pw = new PrintWriter(sw);
e.printStackTrace(pw);
retValue = sw.toString();
} finally {
try {
if (pw != null)
pw.close();
if (sw != null)
sw.close();
} catch (IOException ignore) {
//System.out.println(stackTraceToString(e));
}
}
return retValue;
}
public void doPost(HttpServletRequest request,
HttpServletResponse response) throws ServletException,
IOException {
doGet(request, response);
}
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException,
IOException {
PrintWriter out = response.getWriter();
try {
out.println(getServerStatusLocal());
} catch (Exception e) {
out.println(stackTraceToString(e));
}
}
public String getServerStatusLocal() {
MBeanServerConnection myCon;
try {
myCon = getLocalConnection();
} catch (NamingException e) {
//no MBean connection; server not ready
return stackTraceToString(e);
}
return getSOAPlatformStatus(myCon);
}
public static void main(String[] args) {
String host = "192.168.178.17";
String port = "7001";
String user = "weblogic";
String password = "xxx";
MBeanServerConnection myCon;
try {
myCon = getRemoteConnection(host, port, user, password);
//Set<ObjectName> myObjs = myCon.queryNames(new ObjectName("*:j2eeType=CompositeLifecycleConfig,*"), null);
//for (ObjectName myObj : myObjs) {
// System.out.println(myObj.getCanonicalName());
//}
System.out.println(getSOAPlatformStatus(myCon));
} catch (Exception e) {
System.out.println(stackTraceToString(e));
}
}
}
This servlet I could deploy to the managed servers to get the status. This however... failed because of;
javax.management.RuntimeMBeanException: java.lang.SecurityException: MBean attribute access denied.
MBean: oracle.soa.config:name=soa-infra,j2eeType=CompositeLifecycleConfig,Application=soa-infra
Getter for attribute SOAPlatformStatus
Detail: Access denied. Required roles: Admin, Operator, Monitor, executing subject: principals=[]
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.rethrow(DefaultMBeanServerInterceptor.java:856)
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.rethrowMaybeMBeanException(DefaultMBeanServerInterceptor.java:869)
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.getAttribute(DefaultMBeanServerInterceptor.java:670)
at com.sun.jmx.mbeanserver.JmxMBeanServer.getAttribute(JmxMBeanServer.java:638)
So I thought I could maybe deploy this as part of a BPEL process. When running in another context, these SecurityExceptions might not be raised. When refactoring the code and testing the BPEL process however I still got the same exception.
Accessing the MBean
I found; http://docs.oracle.com/cd/E11035_01/wls100/security/thin_client.html#wp1046345 and got back to my servlet code. Then I added a weblogic.xml deployment descriptor, a role to web.xml and a role mapping to weblogic.xml and it worked! The code can be downloaded from; https://dl.dropbox.com/u/6693935/blog/DetermineServerStatus.zip
The BPEL code is for reference purposes only. I haven't applied the role assignment to the BPEL code. The servlet has an additional benefit that it is more easily tweakable to the response wanted by the loadbalancer
Below a screenshot of the result when the server is fully started.

We performed the following test to confirm the expected behavior.
- first deploy the servlet to the managed servers in a cluster
- confirm the servlet output for the managed servers is true (by accessing them directly, not via a loadbalancer)
- shutdown one node and confirm the servlet cannot be accessed. confirm the other node still replies 'true'
- start the node and wait till it has state Running
- confirm the servlet output for that node is false and for the other node is true
- wait a while (until all processes are loaded)
- confirm that for both nodes the servlet output is true
Friday, April 27, 2012
Things to mind in a clustered SOA Suite 11g environment
Introduction
When working in a clustered environment, there are several challenges which need to be taken into account. I've encountered and documented several of them in this post.
It is always wise to use the latest version of the software and keep your version up to date with regular patches. Oracle SOA Suite 11g is the first SOA Suite on Weblogic server and Oracle has done a great job on migrating several engines from OC4J to Weblogic. Also they have provided many new and useful features such as the EDN and the MDS. There is still some work to be done though but it will only get better!
Issues
Callbacks do not arrive
When working with SOA Suite 11.1.1.4 in a clustered environment, it is possible asynchronous callbacks do not arrive. The parent process is waiting for a callback, however the child has already send the callback.
When looking at the diagnostics log, the following error is shown;
an unhandled exception has been thrown in the Collaxa Cube systemr; exception reported is: "javax.persistence.PersistenceException: Exception [EclipseLink-4002] (Eclipse Persistence Services - 2.1.3.v20110304-r9073): org.eclipse.persistence.exceptions.DatabaseException
Internal Exception: java.sql.SQLIntegrityConstraintViolationException: ORA-00001: unique constraint (SOA_SOAINFRA.AT_PK) violated
Error Code: 1
Call: INSERT INTO AUDIT_TRAIL (CIKEY, COUNT_ID, NUM_OF_EVENTS, BLOCK_USIZE, CI_PARTITION_DATE, BLOCK_CSIZE, BLOCK, LOG) VALUES (?, ?, ?, ?, ?, ?, ?, ?)
bind => [851450, 5, 0, 118110, 2012-01-12 16:08:04.063, 5048, 3, [B@69157b01]
Query: InsertObjectQuery(com.collaxa.cube.persistence.dto.AuditTrail@494ca627)
at org.eclipse.persistence.internal.jpa.EntityManagerImpl.flush(EntityManagerImpl.java:744)
The solution to this problem is described on;
There are 3 known workarounds;
- shutting down one managed server in the cluster
- disable audit trail logging for processes using asynchronous callbacks (http://albinoraclesoa.blogspot.com/2012/02/oracle-soa-11g-callback-not-reaching.html)
- set the AuditStorePolicy to "async". Howto: SOA Administration -> BPEL Properties -> More BPEL Configuration Properties. https://support.oracle.com/CSP/main/article?cmd=show&type=BUG&id=9964636
There is one fix;
- install patch; https://support.oracle.com/CSP/main/article?cmd=show&type=NOT&doctype=PROBLEM&id=1338478.1
Depending on the specific situation at a customer such as
- development process
- application server maintenance process
- time available
- local legislation
The best option for a specific customer can differ.
Database adapter
For polling issues see: http://javaoraclesoa.blogspot.com/2012/04/polling-with-dbadapter-in-clustered.html
Oracle recommends putting the configuration plan for the JCA adapters (such as the DbAdapter) on a shared storage. If a customer has not done this, the Plan.xml needs to be copied manually to other managed servers in a cluster after every change. If this is not done, the managed servers can have different (mismatched) configurations on the managed servers which can cause unexpected results.
Scheduling using Quartz
Scheduling using a servlet is described in; http://www.oracle.com/technetwork/middleware/soasuite/learnmore/soascheduler-186798.pdf
This can cause issues in a clustered environment depending on the specific implementation
In a clustered environment it is better to use EDN business events and DBMS_SCHEDULER;
See: http://javaoraclesoa.blogspot.com/2012/04/scheduling-edn-business-events-using.html
Test console does not function in Enterprise Manager
In a clustered environment which is installed using Oracle's Enterprise Deployment Guide, when using the Enterprise Manager, the WSDL URL of the test console (available to test a webservice) which is generated can be a managed server specific URL. This URL is in certain setups not directly available. This can be fixed by manually replacing the URL of the managed server with the URL of the loadbalancer and then click the Parse button.
Environment specific issues
It is not known if the below issues are bugs or caused by misconfiguration of the server. They have been observed on one installation at a specific customer (11.1.1.4).
Deployment issues
Deployment (using Ant scripts) does not always (it works most of the time...) roll out a process to both managed servers in a cluster. I have not found the cause of this issue and I'm not sure if this is a known bug. It is however wise to check that a process is deployed to all managed servers in a cluster and if one branch does not contain the process, repeat the deployment till it does.
Partition creation
After creation of a partition, it was only present on one managed server in the cluster. Removing the partition and recreating it solved this issue.
Conclusion
There are some challenges when working on a clustered environment. I will expand this post when I find more issues or things to mind. For a predictable development process it is wise to use a clustered development environment when production is also clustered so these issues can be solved in development and not first encountered on production.
Friday, April 6, 2012
Polling with the DbAdapter in a clustered environment
Introduction
Most customers use a clustered production environment. The development environment is often not clustered. There are several things to consider for developers when the software developed will eventually run in a clustered environment. It would be a shame if the software has been developed, unit tested, system tested, accepted by the users and then breaks on the production system.
I will first discuss the DbAdapter and polling in this post. This is not a complete description of all the settings which can influence this behavior, just some things I've tried and problems I've encountered.
I've used the (active-active cluster) setup as described in;
http://javaoraclesoa.blogspot.com/2012/03/oracle-soa-suite-cluster-part-1.html
http://javaoraclesoa.blogspot.com/2012/03/oracle-soa-suite-cluster-part-2.html
This article is about the DbAdapter. An error which can occur when using the AqAdapter when dequeueing in a clustered environment is that a message is queued once and dequeued more then once. This can occur in 11.2 databases. Look at; http://www.oracle.com/technetwork/middleware/docs/aiasoarelnotesps5-1455925.html for a description on how to fix this. Below has been copied from the mentioned document;
Bug: 13729601
Added: 20-February-2012
Platform: All
The dequeuer returns the same message in multiple threads in high concurrency environments when Oracle database 11.2 is used. This means that some messages are dequeued more than once. For example, in Oracle SOA Suite, if Service 1 suddenly raises a large number of business events that are subscribed to by Service 2, duplicate instances of Service 2 triggered by the same event may be seen in an intermittent fashion. The same behavior is not observed with a 10.2.0.5 database or in an 11.2 database with event10852 level 16384 set to disable the 11.2 dequeue optimizations.
Workaround: Perform the following steps:
Log in to the 11.2 database:
CONNECT /AS SYSDBA
Specify the following SQL command in SQL*Plus to disable the 11.2 dequeue optimizations:
SQL> alter system set event='10852 trace name context forever,
level 16384'scope=spfile;
Polling setup
In an active/active cluster configuration, a deployed process will have two instances of a process polling on the same table. In this case it is important to consider if it will be a problem if more then one instance picks up the same entry in the table.
I used the following database setup to simulate and log the test
The script contains three tables;
POLLING_TEST_CLUSTER
- this table will be used by the DbAdapter for polling
POLLING_TEST_LOG
- this table will log status changes in POLLING_TEST_CLUSTER (POLLING_TEST_CLUSTER has a before update trigger)
POLLING_TEST_OUTPUT
- a BPEL process will read from POLLING_TEST_CLUSTER and put entries in this table. this table has a unique constraint on the ID column. the same ID is used as in POLLING_TEST_CLUSTER thus if the same entry from the POLLING_TEST_CLUSTER table is picked up twice by BPEL, it will cause a unique key constraint when it tries to insert the entry in POLLING_TEST_CLUSTER
I've used a 'pragma autonomous_transaction' in the logging procedure. This will fail (with an ORA-06519: active autonomous transaction detected and rolled back) if I don't end the procedure with an explicit commit.
Next configure a datasource and the database adapter in the Weblogic Console so you can use them in BPEL. Don't create an XA datasource! It will cause problems with autonomous transactions such as java.sql.SQLException: Cannot call rollback when using distributed transactions (XA datasources can also cause problems with database links; http://javaoraclesoa.blogspot.com/2012/02/exception-occured-when-binding-was.html)
When configuring the DbAdapter, keep in mind that you have to copy the Plan.xml file (deployment plan for the DbAdapter) to the other managed server if you have not configured a shared storage for this file (which is suggested in the Enterprise Deployment Guide, http://docs.oracle.com/cd/E17904_01/core.1111/e12036/extend_soa.htm, paragraph 5.21.1). If you don't do this, the connection factory will not be available in the other managed server.
Polling test
You can download the processes here
I created a small process to insert a record in the POLLING_TEST_CLUSTER table with a status NEW so it would directly be picked up. I used SOAPUI (http://www.soapui.org/) to do a stress test and call this process a large number of times.
I was able to produce the error (a small number of times at high loads) that two instances of the adapter, running on different servers in the cluster, picked up and processed a message at the same time. I have also seen this happening at a customer.
In my setup this situation would cause a unique constraint violation as shown below;
<bpelFault><faultType>0</faultType><bindingFault xmlns="http://schemas.oracle.com/bpel/extension"><part name="summary"><summary>Exception occured when binding was invoked. Exception occured during invocation of JCA binding: "JCA Binding execute of Reference operation 'insert' failed due to: DBWriteInteractionSpec Execute Failed Exception. insert failed. Descriptor name: [write_textline_DB.PollingTestOutput]. Caused by java.sql.BatchUpdateException: ORA-00001: unique constraint (TESTUSER.POLLING_TEST_OUTPUT_PK) violated . Please see the logs for the full DBAdapter logging output prior to this exception. This exception is considered not retriable, likely due to a modelling mistake. To classify it as retriable instead add property nonRetriableErrorCodes with value "-1" to your deployment descriptor (i.e. weblogic-ra.xml). To auto retry a retriable fault set these composite.xml properties for this invoke: jca.retry.interval, jca.retry.count, and jca.retry.backoff. All properties are integers. ". The invoked JCA adapter raised a resource exception. Please examine the above error message carefully to determine a resolution. </summary></part><part name="detail"><detail>ORA-00001: unique constraint (TESTUSER.POLLING_TEST_OUTPUT_PK) violated </detail></part><part name="code"><code>1</code></part></bindingFault></bpelFault>
This occurred even with the NumberOfThreads value set to 1 (this is the default);

Below I will describe two possible solutions for this issue and my experience with it. Distributed polling and using a Reserved Value.
Distributed Polling
This is also described more extensively in; http://www.oracle.com/technetwork/database/features/availability/maa-soa-assesment-194432.pdf
It is possible to set the DbAdapter property to do distributed polling;

Distributed Polling means that when a record is read, it is locked by the reading instance. Another instance which wants to pickup the record skips locked records. This can however cause problems with locks which could originate from different sources then the processes; records which would require processing, could be skipped.
Also, a BPEL process is by default invoked asynchronously by the DbAdapter;

This causes the lock to be released right after the DbAdapter is done with it and the BPEL process is started. This makes a case for using the logical delete provided in the DbAdapter if you want to use this mechanism and not update the field later in the BPEL process.
Using distributed polling in combination with logical delete is however not recommended by Oracle; from the manual (Help button in the JDeveloper wizard); A better alternative is to set either NumberOfThreads or MarkReservedValue for logical delete or delete strategies.
I tested the same process with distributed polling enabed. Still a small number of processes failed with a unique key constraint thus this mechanism is not 100% safe. I did get a bit better results however.
Unread and reserved value
Unread Value
Setting the Unread value causes the select query used for polling to contain a where clause matching the field to the Unread value. During my test I found that setting the Unread value in the DbAdapter configuration wizard caused my process not to pickup records with the set value. I have however seen at customers that this value was used succesfully to limit the records being picked up.
The help documentation says the following (which made me doubt the purpose of this field); Unread Value
(Optional) Enter an explicit value to indicate that the row does not need to be read. During polling, this row is skipped.


Reserved value
In the release notes of SOA Suite 11.1.1.4 (https://supporthtml.oracle.com/epmos/faces/ui/km/SearchDocDisplay.jspx?_afrLoop=3308018508015000&type=DOCUMENT&id=1290512.1&displayIndex=3&_afrWindowMode=0&_adf.ctrl-state=y8cqyff7j_134), the following is documented;
18.1.5.1 Distributed Polling Using MarkReservedValue Disabled by Default
In this release, Oracle recommends that you use the new distributed polling approach based on skip locking. When editing an Oracle Database Adapter service which has a MarkReservedValue set, that value will be removed to enable the new best practice. To use the old distributed polling approach based on a reserved value, select the value from the drop down menu.
In the help in JDeveloper, the following is documented for distributed polling (skip locking as mentioned above); Distributed Polling. Select this checkbox if distributed polling is required. However, this implementation uses a SELECT FOR UPDATE command. A better alternative is to set either NumberOfThreads or MarkReservedValue for logical delete or delete strategies.
As you can see in the above screenshots, it is possible to set a reserved value.

This reserved value (MarkReservedValue in *_db.jca) causes an instance of the process to set an identifier. This identifier is skipped by the other polling instances in the cluster.
When I however tried to use this setting (Reserved Value) in 11.1.1.6 (of course setting the Unread value to ''), I noticed the DbAdapter did not pickup any messages. When changing the Read Value and redeploying (after emptying the reserved value), it did pickup messages again immediately. I'm not sure why it didn't work in this test. My guess is for this to work, an additional setting is required. If I've found this setting, I will update this post. Also notice the wizard empties the Reserved Value if you go through it again. For the time being, I'll use the skip locking setting (distributed polling).
Singleton DbAdapter
Based on a suggestion done in the comments of this post, there is also the option to configure the DbAdapter as a singleton with a JCA property.
See the documentation for more information on this;
http://docs.oracle.com/cd/E23943_01/integration.1111/e10231/life_cycle.htm#BABDAFBH
The behavior of this property is described in the following post; http://ayshaabbas.blogspot.nl/2012/11/db-adapter-singleton-behaviour-in-high.html
Most customers use a clustered production environment. The development environment is often not clustered. There are several things to consider for developers when the software developed will eventually run in a clustered environment. It would be a shame if the software has been developed, unit tested, system tested, accepted by the users and then breaks on the production system.
I will first discuss the DbAdapter and polling in this post. This is not a complete description of all the settings which can influence this behavior, just some things I've tried and problems I've encountered.
I've used the (active-active cluster) setup as described in;
http://javaoraclesoa.blogspot.com/2012/03/oracle-soa-suite-cluster-part-1.html
http://javaoraclesoa.blogspot.com/2012/03/oracle-soa-suite-cluster-part-2.html
This article is about the DbAdapter. An error which can occur when using the AqAdapter when dequeueing in a clustered environment is that a message is queued once and dequeued more then once. This can occur in 11.2 databases. Look at; http://www.oracle.com/technetwork/middleware/docs/aiasoarelnotesps5-1455925.html for a description on how to fix this. Below has been copied from the mentioned document;
Bug: 13729601
Added: 20-February-2012
Platform: All
The dequeuer returns the same message in multiple threads in high concurrency environments when Oracle database 11.2 is used. This means that some messages are dequeued more than once. For example, in Oracle SOA Suite, if Service 1 suddenly raises a large number of business events that are subscribed to by Service 2, duplicate instances of Service 2 triggered by the same event may be seen in an intermittent fashion. The same behavior is not observed with a 10.2.0.5 database or in an 11.2 database with event10852 level 16384 set to disable the 11.2 dequeue optimizations.
Workaround: Perform the following steps:
Log in to the 11.2 database:
CONNECT /AS SYSDBA
Specify the following SQL command in SQL*Plus to disable the 11.2 dequeue optimizations:
SQL> alter system set event='10852 trace name context forever,
level 16384'scope=spfile;
Polling setup
In an active/active cluster configuration, a deployed process will have two instances of a process polling on the same table. In this case it is important to consider if it will be a problem if more then one instance picks up the same entry in the table.
I used the following database setup to simulate and log the test
The script contains three tables;
POLLING_TEST_CLUSTER
- this table will be used by the DbAdapter for polling
POLLING_TEST_LOG
- this table will log status changes in POLLING_TEST_CLUSTER (POLLING_TEST_CLUSTER has a before update trigger)
POLLING_TEST_OUTPUT
- a BPEL process will read from POLLING_TEST_CLUSTER and put entries in this table. this table has a unique constraint on the ID column. the same ID is used as in POLLING_TEST_CLUSTER thus if the same entry from the POLLING_TEST_CLUSTER table is picked up twice by BPEL, it will cause a unique key constraint when it tries to insert the entry in POLLING_TEST_CLUSTER
I've used a 'pragma autonomous_transaction' in the logging procedure. This will fail (with an ORA-06519: active autonomous transaction detected and rolled back) if I don't end the procedure with an explicit commit.
Next configure a datasource and the database adapter in the Weblogic Console so you can use them in BPEL. Don't create an XA datasource! It will cause problems with autonomous transactions such as java.sql.SQLException: Cannot call rollback when using distributed transactions (XA datasources can also cause problems with database links; http://javaoraclesoa.blogspot.com/2012/02/exception-occured-when-binding-was.html)
When configuring the DbAdapter, keep in mind that you have to copy the Plan.xml file (deployment plan for the DbAdapter) to the other managed server if you have not configured a shared storage for this file (which is suggested in the Enterprise Deployment Guide, http://docs.oracle.com/cd/E17904_01/core.1111/e12036/extend_soa.htm, paragraph 5.21.1). If you don't do this, the connection factory will not be available in the other managed server.
Polling test
You can download the processes here
I created a small process to insert a record in the POLLING_TEST_CLUSTER table with a status NEW so it would directly be picked up. I used SOAPUI (http://www.soapui.org/) to do a stress test and call this process a large number of times.
I was able to produce the error (a small number of times at high loads) that two instances of the adapter, running on different servers in the cluster, picked up and processed a message at the same time. I have also seen this happening at a customer.
In my setup this situation would cause a unique constraint violation as shown below;
<bpelFault><faultType>0</faultType><bindingFault xmlns="http://schemas.oracle.com/bpel/extension"><part name="summary"><summary>Exception occured when binding was invoked. Exception occured during invocation of JCA binding: "JCA Binding execute of Reference operation 'insert' failed due to: DBWriteInteractionSpec Execute Failed Exception. insert failed. Descriptor name: [write_textline_DB.PollingTestOutput]. Caused by java.sql.BatchUpdateException: ORA-00001: unique constraint (TESTUSER.POLLING_TEST_OUTPUT_PK) violated . Please see the logs for the full DBAdapter logging output prior to this exception. This exception is considered not retriable, likely due to a modelling mistake. To classify it as retriable instead add property nonRetriableErrorCodes with value "-1" to your deployment descriptor (i.e. weblogic-ra.xml). To auto retry a retriable fault set these composite.xml properties for this invoke: jca.retry.interval, jca.retry.count, and jca.retry.backoff. All properties are integers. ". The invoked JCA adapter raised a resource exception. Please examine the above error message carefully to determine a resolution. </summary></part><part name="detail"><detail>ORA-00001: unique constraint (TESTUSER.POLLING_TEST_OUTPUT_PK) violated </detail></part><part name="code"><code>1</code></part></bindingFault></bpelFault>
This occurred even with the NumberOfThreads value set to 1 (this is the default);

Below I will describe two possible solutions for this issue and my experience with it. Distributed polling and using a Reserved Value.
Distributed Polling
This is also described more extensively in; http://www.oracle.com/technetwork/database/features/availability/maa-soa-assesment-194432.pdf
It is possible to set the DbAdapter property to do distributed polling;

Distributed Polling means that when a record is read, it is locked by the reading instance. Another instance which wants to pickup the record skips locked records. This can however cause problems with locks which could originate from different sources then the processes; records which would require processing, could be skipped.
Also, a BPEL process is by default invoked asynchronously by the DbAdapter;

This causes the lock to be released right after the DbAdapter is done with it and the BPEL process is started. This makes a case for using the logical delete provided in the DbAdapter if you want to use this mechanism and not update the field later in the BPEL process.
Using distributed polling in combination with logical delete is however not recommended by Oracle; from the manual (Help button in the JDeveloper wizard); A better alternative is to set either NumberOfThreads or MarkReservedValue for logical delete or delete strategies.
I tested the same process with distributed polling enabed. Still a small number of processes failed with a unique key constraint thus this mechanism is not 100% safe. I did get a bit better results however.
Unread and reserved value
Unread Value
Setting the Unread value causes the select query used for polling to contain a where clause matching the field to the Unread value. During my test I found that setting the Unread value in the DbAdapter configuration wizard caused my process not to pickup records with the set value. I have however seen at customers that this value was used succesfully to limit the records being picked up.
The help documentation says the following (which made me doubt the purpose of this field); Unread Value
(Optional) Enter an explicit value to indicate that the row does not need to be read. During polling, this row is skipped.

The below image showed a setting that did work.

Reserved value
In the release notes of SOA Suite 11.1.1.4 (https://supporthtml.oracle.com/epmos/faces/ui/km/SearchDocDisplay.jspx?_afrLoop=3308018508015000&type=DOCUMENT&id=1290512.1&displayIndex=3&_afrWindowMode=0&_adf.ctrl-state=y8cqyff7j_134), the following is documented;
18.1.5.1 Distributed Polling Using MarkReservedValue Disabled by Default
In this release, Oracle recommends that you use the new distributed polling approach based on skip locking. When editing an Oracle Database Adapter service which has a MarkReservedValue set, that value will be removed to enable the new best practice. To use the old distributed polling approach based on a reserved value, select the value from the drop down menu.
In the help in JDeveloper, the following is documented for distributed polling (skip locking as mentioned above); Distributed Polling. Select this checkbox if distributed polling is required. However, this implementation uses a SELECT FOR UPDATE command. A better alternative is to set either NumberOfThreads or MarkReservedValue for logical delete or delete strategies.
As you can see in the above screenshots, it is possible to set a reserved value.

This reserved value (MarkReservedValue in *_db.jca) causes an instance of the process to set an identifier. This identifier is skipped by the other polling instances in the cluster.
When I however tried to use this setting (Reserved Value) in 11.1.1.6 (of course setting the Unread value to ''), I noticed the DbAdapter did not pickup any messages. When changing the Read Value and redeploying (after emptying the reserved value), it did pickup messages again immediately. I'm not sure why it didn't work in this test. My guess is for this to work, an additional setting is required. If I've found this setting, I will update this post. Also notice the wizard empties the Reserved Value if you go through it again. For the time being, I'll use the skip locking setting (distributed polling).
Singleton DbAdapter
Based on a suggestion done in the comments of this post, there is also the option to configure the DbAdapter as a singleton with a JCA property.
See the documentation for more information on this;
http://docs.oracle.com/cd/E23943_01/integration.1111/e10231/life_cycle.htm#BABDAFBH
The behavior of this property is described in the following post; http://ayshaabbas.blogspot.nl/2012/11/db-adapter-singleton-behaviour-in-high.html
Sunday, March 25, 2012
Oracle SOA Suite Cluster part 2
Introduction
This is the second part in which I describe the configuration of a Weblogic Cluster. Quick and easy. This does not conform to the Oracle Enterprise Deployment Guide (http://docs.oracle.com/cd/E16764_01/core.1111/e12036/toc.htm) and should thus not be used for enterprise installations. I for example don't install Oracle HTTP server.
This part consists of installation of
- Load balancer
- RCU (Repository creation utility)
- Weblogic server and SOA Suite
- Configure the Nodemanager
- Transport the managed domain to the other machine
- Start the cluster
Load balancer
By using the load balancer URL when referring to other processes, I can do process call distribution. The idea of this setup is illustrated in part 1.
For the load balancer I used pound which can be downloaded at; http://pkgs.repoforge.org/pound/
I downloaded it and installed the rpm using (as root); rpm -i pound-2.4.3-1.el5.rf.x86_64.rpm
I used the below configuration. The host running the load balancer (and database) is 192.168.1.160. The hosts which will run the Weblogic servers are 192.168.1.161 and 192.168.1.162.
User "nobody"
Group "nobody"
## Main listening ports
ListenHTTP
Address 192.168.1.160
Port 8001
End
Service
BackEnd
Address 192.168.1.161
Port 8001
End
BackEnd
Address 192.168.1.162
Port 8001
End
Session
Type Cookie
ID "JSESSIONID"
TTL 300
End
End
RCU
As shown in the image below, I installed the required schema's. No errors this time with the Oracle Enterprise Scheduler schema such as when I used the Database XE 11r2 installation thus it is a good idea to use the Enterprise Edition database.

Weblogic server and SOA Suite
The below is based on the Oracle documentation; http://docs.oracle.com/cd/E23943_01/web.1111/e13709/setup.htm#CLUST431
I choose 2 different virtual machines to install the Weblogic servers on. I did this to be able to identify the challenges which need to be overcome when the server instances are running on different machines (and with different IP addresses). It is of course also possible to install the Weblogic cluster on a single machine, but that would not be sufficient to identify points of attention when developing against a production clustered environment at customers.
First a few basic things;
I started as followed;
Host 1;
keytool -genkey -alias server01 -keyalg RSA -keysize 1024 -dname "CN=Puneeth, OU=Oracle, O=BEA, L=Denver, ST=Colorado, C=US" -keypass password -keystore identity.jks -storepass password
keytool -selfcert -v -alias server01 -keypass password -keystore identity.jks -storepass password -storetype jks
keytool -export -v -alias server01 -file rootCA01.der -keystore identity.jks -storepass password
keytool -import -v -trustcacerts -alias server01 -file rootCA01.der -keystore trust.jks -storepass password
Host 2;
keytool -genkey -alias server02 -keyalg RSA -keysize 1024 -dname "CN=Puneeth, OU=Oracle, O=BEA, L=Denver, ST=Colorado, C=US" -keypass password -keystore identity.jks -storepass password
keytool -selfcert -v -alias server02 -keypass password -keystore identity.jks -storepass password -storetype jks
keytool -export -v -alias server02 -file rootCA02.der -keystore identity.jks -storepass password
keytool -import -v -trustcacerts -alias server02 -file rootCA02.der -keystore trust.jks -storepass password
Copy rootCA01.der and rootCA02.der to both servers. Then on server 1 do;
keytool -import -v -trustcacerts -alias server02 -file rootCA02.der -keystore trust.jks -storepass password
and on server 2 do;
keytool -import -v -trustcacerts -alias server01 -file rootCA01.der -keystore trust.jks -storepass password
I also did the changes to nodemanager.properties, setDomainEnv, startNodemanager and the Weblogic server SSL certificate configuration as described at the previously mentioned location. This SSL configuration will prevent the following error from occurring when the nodemanager is started and you try to access it from the Weblogic console.
<Mar 25, 2012 1:31:34 PM CEST> <Warning> <Security> <BEA-090482> <BAD_CERTIFICATE alert was received from localhost.localdomain - 127.0.0.1. Check the peer to determine why it rejected the certificate chain (trusted CA configuration, hostname verification). SSL debug tracing may be required to determine the exact reason the certificate was rejected.>
<Mar 25, 2012 1:31:34 PM> <WARNING> <Uncaught exception in server handlerjavax.net.ssl.SSLKeyException: [Security:090482]BAD_CERTIFICATE alert was received from localhost.localdomain - 127.0.0.1. Check the peer to determine why it rejected the certificate chain (trusted CA configuration, hostname verification). SSL debug tracing may be required to determine the exact reason the certificate was rejected.>
Transport the domain
Use pack to create a template and transport it to the other machine; http://docs.oracle.com/cd/E23943_01/web.1111/e14144/tasks.htm#WLDPU136
pack.sh is present in several locations;
/u01/app/fmw/Oracle_SOA1/common/bin/pack.sh
/u01/app/fmw/oracle_common/common/bin/pack.sh
/u01/app/fmw/wlserver_10.3/common/bin/pack.sh
I've used the one in the OracleSOA1 folder
On the machine on which you created the domain;
/u01/app/fmw/Oracle_SOA1/common/bin/pack.sh -managed=true -domain=/u01/app/fmw/user_projects/domains/soa_domain -template=misakimw1.jar -template_name="misakimw1"
On the other machine which will be running the managed domain;
/u01/app/fmw/Oracle_SOA1/common/bin/unpack.sh -domain=/u01/app/fmw/user_projects/domains/soa_domain -template=/home/oracle/misakimw1.jar
Starting the cluster
First start the database machine. Pound (the load balancer) is optional at this point and becomes important when starting with experiments on process call load balancing. Then start the nodemanager on both machines. Then start the administration server. From the Weblogic console you can then start both managed domains. This is how it looks in the enterprise manager when it is all started;
 When you deploy, you deploy to the admin server. The admin server makes sure the different managed servers get the processes.
When you deploy, you deploy to the admin server. The admin server makes sure the different managed servers get the processes.

I will start experimenting on this setup shortly and compare it to production environments.
This is the second part in which I describe the configuration of a Weblogic Cluster. Quick and easy. This does not conform to the Oracle Enterprise Deployment Guide (http://docs.oracle.com/cd/E16764_01/core.1111/e12036/toc.htm) and should thus not be used for enterprise installations. I for example don't install Oracle HTTP server.
This part consists of installation of
- Load balancer
- RCU (Repository creation utility)
- Weblogic server and SOA Suite
- Configure the Nodemanager
- Transport the managed domain to the other machine
- Start the cluster
Load balancer
By using the load balancer URL when referring to other processes, I can do process call distribution. The idea of this setup is illustrated in part 1.
For the load balancer I used pound which can be downloaded at; http://pkgs.repoforge.org/pound/
I downloaded it and installed the rpm using (as root); rpm -i pound-2.4.3-1.el5.rf.x86_64.rpm
I used the below configuration. The host running the load balancer (and database) is 192.168.1.160. The hosts which will run the Weblogic servers are 192.168.1.161 and 192.168.1.162.
User "nobody"
Group "nobody"
## Main listening ports
ListenHTTP
Address 192.168.1.160
Port 8001
End
Service
BackEnd
Address 192.168.1.161
Port 8001
End
BackEnd
Address 192.168.1.162
Port 8001
End
Session
Type Cookie
ID "JSESSIONID"
TTL 300
End
End
RCU
As shown in the image below, I installed the required schema's. No errors this time with the Oracle Enterprise Scheduler schema such as when I used the Database XE 11r2 installation thus it is a good idea to use the Enterprise Edition database.

Weblogic server and SOA Suite
The below is based on the Oracle documentation; http://docs.oracle.com/cd/E23943_01/web.1111/e13709/setup.htm#CLUST431
I choose 2 different virtual machines to install the Weblogic servers on. I did this to be able to identify the challenges which need to be overcome when the server instances are running on different machines (and with different IP addresses). It is of course also possible to install the Weblogic cluster on a single machine, but that would not be sufficient to identify points of attention when developing against a production clustered environment at customers.
First a few basic things;
- start the installation of the Weblogic server as followed; java -d64 -jar wlsXXX_generic.jar. Then install the SOA Suite
- set the server to listen on all local addresses. References to localhost will cause problems
- Use the configuration wizard (/u01/app/fmw/wlserver_10.3/common/bin/config.sh in my case; http://docs.oracle.com/cd/E23943_01/web.1111/e14140/configuration_screens.htm#WLDCW112 to create an Administration domain, a Managed domain and a cluster. See also http://biemond.blogspot.com/2008/11/build-your-own-weblogic-103-cluster.html for some screenshots on how to configure the cluster.
weblogic.security.SecurityInitializationException: The dynamic loading of the OPSS java security policy provider class oracle.security.jps.internal.policystore.JavaPolicyProvider failed due to problem inside OPSS java security policy provider. Exception was thrown when loading or setting the JPSS policy provider. Enable the debug flag -Djava.security.debug=jpspolicy to get more information. Error message: JPS-01538: The default policy provider was not found. at weblogic.security.service.CommonSecurityServiceManagerDelegateImpl.loadOPSSPolicy(CommonSecurityServiceManagerDelegateImpl.java:1394)
Configure the nodemanager
To make it possible to use the nodemanager, you need to configure SSL for the server, keystore, truststore etc. Look at; http://wls4mscratch.wordpress.com/2010/05/31/configure-node-manager-over-ssl-custom-certifcates/.
Configure the nodemanager
To make it possible to use the nodemanager, you need to configure SSL for the server, keystore, truststore etc. Look at; http://wls4mscratch.wordpress.com/2010/05/31/configure-node-manager-over-ssl-custom-certifcates/.
I started as followed;
Host 1;
keytool -genkey -alias server01 -keyalg RSA -keysize 1024 -dname "CN=Puneeth, OU=Oracle, O=BEA, L=Denver, ST=Colorado, C=US" -keypass password -keystore identity.jks -storepass password
keytool -selfcert -v -alias server01 -keypass password -keystore identity.jks -storepass password -storetype jks
keytool -export -v -alias server01 -file rootCA01.der -keystore identity.jks -storepass password
keytool -import -v -trustcacerts -alias server01 -file rootCA01.der -keystore trust.jks -storepass password
Host 2;
keytool -genkey -alias server02 -keyalg RSA -keysize 1024 -dname "CN=Puneeth, OU=Oracle, O=BEA, L=Denver, ST=Colorado, C=US" -keypass password -keystore identity.jks -storepass password
keytool -selfcert -v -alias server02 -keypass password -keystore identity.jks -storepass password -storetype jks
keytool -export -v -alias server02 -file rootCA02.der -keystore identity.jks -storepass password
keytool -import -v -trustcacerts -alias server02 -file rootCA02.der -keystore trust.jks -storepass password
Copy rootCA01.der and rootCA02.der to both servers. Then on server 1 do;
keytool -import -v -trustcacerts -alias server02 -file rootCA02.der -keystore trust.jks -storepass password
and on server 2 do;
keytool -import -v -trustcacerts -alias server01 -file rootCA01.der -keystore trust.jks -storepass password
I also did the changes to nodemanager.properties, setDomainEnv, startNodemanager and the Weblogic server SSL certificate configuration as described at the previously mentioned location. This SSL configuration will prevent the following error from occurring when the nodemanager is started and you try to access it from the Weblogic console.
<Mar 25, 2012 1:31:34 PM CEST> <Warning> <Security> <BEA-090482> <BAD_CERTIFICATE alert was received from localhost.localdomain - 127.0.0.1. Check the peer to determine why it rejected the certificate chain (trusted CA configuration, hostname verification). SSL debug tracing may be required to determine the exact reason the certificate was rejected.>
<Mar 25, 2012 1:31:34 PM> <WARNING> <Uncaught exception in server handlerjavax.net.ssl.SSLKeyException: [Security:090482]BAD_CERTIFICATE alert was received from localhost.localdomain - 127.0.0.1. Check the peer to determine why it rejected the certificate chain (trusted CA configuration, hostname verification). SSL debug tracing may be required to determine the exact reason the certificate was rejected.>
Transport the domain
Use pack to create a template and transport it to the other machine; http://docs.oracle.com/cd/E23943_01/web.1111/e14144/tasks.htm#WLDPU136
pack.sh is present in several locations;
/u01/app/fmw/Oracle_SOA1/common/bin/pack.sh
/u01/app/fmw/oracle_common/common/bin/pack.sh
/u01/app/fmw/wlserver_10.3/common/bin/pack.sh
I've used the one in the OracleSOA1 folder
On the machine on which you created the domain;
/u01/app/fmw/Oracle_SOA1/common/bin/pack.sh -managed=true -domain=/u01/app/fmw/user_projects/domains/soa_domain -template=misakimw1.jar -template_name="misakimw1"
On the other machine which will be running the managed domain;
/u01/app/fmw/Oracle_SOA1/common/bin/unpack.sh -domain=/u01/app/fmw/user_projects/domains/soa_domain -template=/home/oracle/misakimw1.jar
Starting the cluster
First start the database machine. Pound (the load balancer) is optional at this point and becomes important when starting with experiments on process call load balancing. Then start the nodemanager on both machines. Then start the administration server. From the Weblogic console you can then start both managed domains. This is how it looks in the enterprise manager when it is all started;
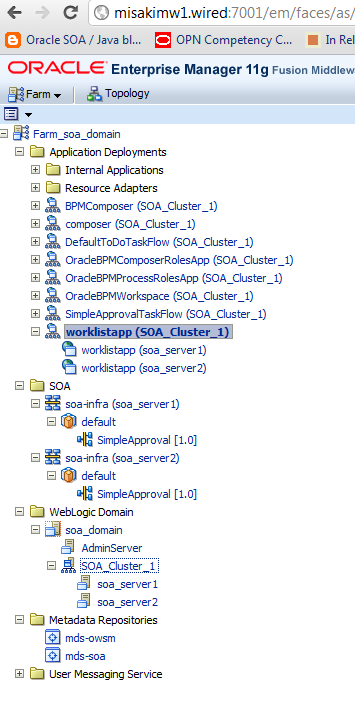

Subscribe to:
Posts (Atom)