Large Language Models (LLMs) are transforming natural language processing, enabling advanced applications like chatbots, content generation, and more. Running LLMs locally provides enhanced privacy, control, and performance. This guide will walk you through setting up LLMs on your local machine.
While hardware requirements and required technical knowledge can pose a challenge, selecting the right tools simplifies the process. I recommend starting with LM Studio for its user-friendly GUI and Ollama for a robust CLI tool. This blog post aims to help you get started quickly and provides essential background information.
Why run a model locally?
Large companies like OpenAI, Microsoft and Google dominate the LLM market. These companies often restrict the output of their models and keep the underlying logic and training data proprietary. Additionally, there are usage costs involved.
To prevent unethical, dangerous, or discriminatory outputs, these companies implement several measures:
- Limit Training Material: The data used for training is often non-transparent.
- Filter Prompts: Offensive language and sensitive topics are blocked.
- Filter Model Output: Outputs are monitored to ensure alignment with the company's guidelines.
Furthermore, it is often unclear how your data is handled, with potential sharing with third parties or government agencies. Dependency on third-party hosting can also introduce geopolitical risks.
 |
| Strings Attached |
Running a model locally offers several advantages:
- Data Privacy: All data remains on your local machine, eliminating third-party access.
- Independence: No reliance on external services.
- Cost-Effective: Beyond hardware costs, there are no additional fees.
- Transparency: Use of transparent and uncensored datasets.
- Flexibility: No input or output filters unless you choose to implement them, allowing for unrestricted model use.
- Hands-On Learning: Enables experimentation and a deeper understanding of LLM technology.
- DIY Flexibility: Offers greater flexibility and control compared to commercial service limitations.
Model
When choosing a model to run locally, consider the following factors:
- Model Size and Accuracy
- Bigger Models
are generally more accurate (smarter, more emergent capabilities) but require more resources. - Number of Parameters
More parameters often mean smarter models but higher memory/CPU needs. For instance, Llama 3 70B has 70 billion parameters.
- Model Formats and Trade-offs
- Resource Use
Pytorch is resource-intensive but great for fine-tuning, while GGUF and GGML are quantized (a form of compression for LLMs), reducing system requirements with minimal accuracy loss. - Hardware Requirements
Some models use both GPU and CPU memory (Pytorch, GGUF, GGML), others are GPU-only (GPTQ, AWQ). GGUF has superseded GGML and AWQ has superseded GPTQ.
- Mixture of Experts (MoE)
- Specialized Models
Combine multiple sub-models for better performance and efficiency. Example: Mixtral 8x22B model uses 39B active parameters from a total of 176B, optimizing resource use.
Personally, I prefer GGUF versions of MoE models. They are not bound to only run on the GPU and are quantized reducing memory requirements. GGUF is models also run more smoothly in my experience when compared to raw Pytorch models. MoE models are generally faster and more efficient on resources than not-MoE models with similar capabilities.
Models can be downloaded from
Huggingface manually or by using a GUI tool like LM Studio of text-generation-webui. For some models you first have to request access. This can be done on the Huggingface website. In addition, Huggingface hosts several leaderboards
such as this one, in which models are compared so you can choose the best one for your specific use case.
Hardware
A general rule for models is that they require ~2GB of RAM per billion parameters for 16-bit precision, and ~1GB for 8-bit precision. For instance, Llama 3 with 70 billion parameters would need around 70GB of RAM at 8-bit precision, or 35GB at 4-bit precision. A smaller model like Llama 3 8B would need about 4GB of RAM at 4-bit precision, making it suitable for systems with limited resources.
NVIDIA graphics cards with high VRAM are beneficial for image generation but can be challenging for large language models due to their size. High VRAM cards are optimal but costly, typically exceeding €10K. CPU RAM is more affordable, with 64GB currently around €250, though it's slower than GPU VRAM due to the absence of specific acceleration features like tensor cores.
Models can often run using a combination of GPU and CPU RAM, or even swap space on Linux, though this is much slower. For those experimenting with the technology, smaller models or quantized versions can significantly reduce hardware requirements. For example, the Microsoft Phi 2 model (2.7B parameters) can run on an 8GB VRAM NVIDIA card or be further reduced with quantization to run on minimal resources, such as a 2GB VRAM card or 2GB CPU RAM.
GUI Solution. LM Studio
There are many GUI tools available for running models locally, each with its own strengths. Among them,
LM Studio stands out as particularly user-friendly. LM Studio is compatible with Windows, Mac, and Linux, offering an intuitive interface for finding, downloading, and running models. It also provides a useful feature that indicates whether your hardware meets the requirements to run a specific model.
How to Use LM Studio:
- Installation: Download and install LM Studio from the official website.
- Model Search: Use the built-in search feature to find models.
- Download and Run: Easily download models and run them.
- Compatibility Check: The tool will check if your hardware can support the selected model avoiding downloads of large models you might not be able to run.
By following these steps, you can efficiently manage and run various models on your local machine.
LM Studio not only provides a user-friendly interface for running models locally but also includes an option to host the model using an OpenAI-compatible API, which is a widely accepted standard. This compatibility allows you to write code that interacts with the model via a local API. However, in my experience, Ollama offers a more robust API.
Text-Generation-WebUI is another tool I've used in the past. Although it supports more model formats, offers several extensions and easily utilizes disk swap space when physical RAM is insufficient, it is less user-friendly compared to LM Studio. Additionally, the OpenAI-compatible API provided by a plugin can be less stable, occasionally leading to crashes. This can be a significant drawback if stability and ease of use are your primary concerns.
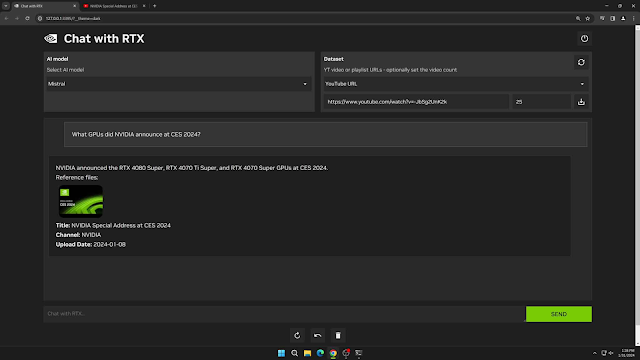
GUI Solution: Chat with RTX
Recently, I encountered an impressive NVidia tool called Chat with RTX. This tool requires a relatively powerful NVidia RTX graphics card (minimum 8GB VRAM) and offers an easy way to interact with local documents, images, and even video. It excels in making Retrieval Augmented Generation (RAG) accessible, providing a user-friendly interface for enhanced data interaction.
There are numerous CLI solutions for hosting models, but I have found Ollama to be particularly user-friendly and robust. Ollama features a model database that simplifies downloading models. You can also utilize models from other sources or ones you already have locally. For the latter, you'll need to find or create an Ollama model format file.
Key Features:
- Installation: Straightforward, with instructions available on their GitHub page.
- Commands: Downloading, running, and hosting models with an API can be done with single commands.
- Model Switching: Ollama can switch between models upon API request, allowing seamless use of specialized models for specific tasks.
Installing Ollama is straightforward, with detailed instructions available on
their GitHub page. Once installed, you can download, run, and host models using single commands.
For example on Linux you can do;
- Install
curl -fsSL https://ollama.com/install.sh | sh - Run
ollama run phi3
This installs ollama and runs Microsofts Phi3 model
A notable feature of Ollama is its ability to switch between models upon API request, allowing for seamless use of specialized models without manual intervention.
You can easily use the ollama's OpenAI compatible API with Python frameworks such as;
- LangChain: Ideal for text generation, language translation, summarization, and classification.
- LlamaIndex: Excels in content generation, document search and retrieval, chatbots, and virtual assistants.
- MetaGPT and AutoGen
Library Solution: llama-cpp-python
This is a barebones solution more suitable to developers or for running models in production. If you want to get started with running models locally, you can install
llama.cpp directly and use it. If you are a Python developer, you can use
llama-cpp-python which provides bindings for llama.cpp and installs it along when you do a pip install llama-cpp-python. This allows you to do things like (mind to first download a suitable model file
from HuggingFace, for example
this one);
from llama_cpp import Llama
llm = Llama(
model_path="./models/7B/llama-model.gguf",
# n_gpu_layers=-1, # Uncomment to use GPU acceleration
# seed=1337, # Uncomment to set a specific seed
# n_ctx=2048, # Uncomment to increase the context window
)
output = llm(
"Q: Name the planets in the solar system? A: ", # Prompt
max_tokens=32, # Generate up to 32 tokens, set to None to generate up to the end of the context window
stop=["Q:", "\n"], # Stop generating just before the model would generate a new question
echo=True # Echo the prompt back in the output
) # Generate a completion, can also call create_completion
print(output)
This will respond with something like (in OpenAI API compatible format);
{
"id": "cmpl-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"object": "text_completion",
"created": 1679561337,
"model": "./models/7B/llama-model.gguf",
"choices": [
{
"text": "Q: Name the planets in the solar system? A: Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune and Pluto.",
"index": 0,
"logprobs": None,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 14,
"completion_tokens": 28,
"total_tokens": 42
}
}
Finally
Running models locally offers greater control, transparency, and flexibility, but choosing the right tools and understanding hardware limitations are crucial. It’s not as difficult as it may seem.
Local models, however, typically don't match the performance of models like GPT-4 or Gemini 1.5 Pro. For instance, Llama 3 70B is currently the best publicly available base model, and fine-tuned versions can offer even better performance. If local models were equivalent to those provided by large companies, users wouldn't pay premium prices for these services.
Limitations of Local Models
- Monomodal: Most local models handle only one type of input, usually text. They can't combine inputs like text, audio, images, video easily.
- Internet Access: Out-of-the-box internet access or external resource integration isn't available. You can however use tool plug-ins or agents to achieve this.
- Licensing: Be mindful of licensing restrictions, especially for commercial use, as some models (e.g., from Meta) have limitations.
By understanding these aspects and leveraging the right tools, running models locally can be a rewarding and practical solution.




No comments:
Post a Comment