
Showing posts with label spring. Show all posts
Showing posts with label spring. Show all posts
Wednesday, April 8, 2020
Spring: Blocking vs non-blocking: R2DBC vs JDBC and WebFlux vs Web MVC
Spring Framework version 5, released in Sept 2017, introduced Spring WebFlux. A fully reactive stack. In Dec 2019 Spring Data R2DBC, a reactive relational database driver was released. In this blog post I'll show that at high concurrency, WebFlux and R2DBC perform better. They have better response times and higher throughput. As additional benefits, they use less memory and CPU per request processed and when leaving out JPA in case of R2DBC, your fat JAR becomes a lot smaller. At high concurrency using WebFlux and R2DBC is a good idea!

Friday, September 27, 2019
Calling an Oracle DB stored procedure from Spring Boot using Apache Camel
There are different ways to create data services. The choice for a specific technology to use, depends on several factors inside the organisation which wishes to realize these services. In this blog post I'll provide a minimal sample on how you can use Spring Boot with Apache Camel to call an Oracle database procedure which returns the result of an SQL query as an XML. You can browse the code here.


Tuesday, September 3, 2019
Microservice framework startup time on different JVMs
When developing microservices, a fast startup time is useful. It can for example reduce the amount of time a rolling upgrade of instances takes and reduce build time thus shortening development cycles. When running your code using a 'serverless' framework such as for example Knative or FnProject, scaling and getting the first instance ready is faster.

When you want to reduce startup time, an obvious thing to look at is ahead of time (AOT) compilation such as provided as an early adopter plugin as part of GraalVM. Several frameworks already support this out of the box such as Helidon SE, Quarkus and Micronaut. Spring will probably follow with version 5.3 Q2 2020. AOT code, although it is fast to startup, still shows differences per framework. Which framework produces the native executable which is fastest to start?
If you need specific libraries which cannot be natively compiled (not even when using the Tracing Agent), using Java the old-fashioned JIT way is also an option. You will not achieve start-up times near AOT start-up times but by choosing the right framework and JVM, it can still be acceptable.
If you need specific libraries which cannot be natively compiled (not even when using the Tracing Agent), using Java the old-fashioned JIT way is also an option. You will not achieve start-up times near AOT start-up times but by choosing the right framework and JVM, it can still be acceptable.
In this blog post I'll provide some measures which I did on start-up times of minimal implementations of several frameworks and an implementation with only Java SE. I've looked at both JIT and AOT (wherever this was possible) and ran the code on different JVMs.
Thursday, February 22, 2018
Java: How to fix Spring @Autowired annotation not working issues
Spring is a powerful framework, but it requires some skill to use efficiently. When I started working with Spring a while ago (actually Spring Boot to develop microservices) I encountered some challenges related to dependency injection and using the @Autowired annotation. In this blog I'll explain the issues and possible solutions. Do note that since I do not have a long history with Spring, the provided solutions might not be the best ones.


Tuesday, January 23, 2018
Getting started with Spring Boot microservices. Why and how.
In order to quickly develop microservices, Spring Boot is a common choice. Why should I be interested in Spring Boot? In this blog post I'll give you some reasons why looking at Spring Boot is interesting and give some samples on how to get started quickly. I'll shortly talk about microservices, move on to Spring Boot and end with Application Container Cloud Service which is an ideal platform to run and manage your Spring Boot applications on. This blog touches many subjects but they fit together nicely. You can view the code of my sample Spring Boot project here. Most of the Spring Boot knowledge has been gained by the following free course by Java Brains.

Friday, October 10, 2014
SOA Suite 12c: Getting started with the Spring Component
The Oracle SOA Suite Spring component has been present since SOA Suite 11.1.1.3 (11gR1 PS2). This component allows easy integration of Java code with other SOA Suite components such as (among others) BPEL, BPM and Business Rules. In SOA Suite 12c (12.1.3.0) this component is still present. In This blog post I will provide a short example on how it can be used and how the first problem I encountered with this component can be avoided.

Wednesday, June 12, 2013
Oracle BPEL and Java. A comparison of different interaction options
When building BPEL processes in Oracle SOA Suite 11g, it sometimes happens some of the required functionality can't easily be created by using provided activities, flow control options and adapters. Often there are Java libraries available which can fill these gaps. This blog post provides an evaluation of different options for making interaction between BPEL and Java possible.
In the examples provided in this post, I'm using the JsonPath library (https://code.google.com/p/json-path/) inside a BPEL process. A usecase for this could be that a webclient calls the BPEL process with a JSON message and BPEL needs to extract fields from that message.
The Java code to execute, is the following;
package ms.testapp;
import com.jayway.jsonpath.JsonPath;
public class JsonPathUtils {
public String ExecuteJsonPath(String jsonstring, String jsonpath) {
String result = JsonPath.read(jsonstring, jsonpath).toString();
return result;
}
public JsonPathUtils() {
super();
}
}
Of course small changes were necessary for the specific integration methods. I provided code samples at the end of this post for every method.
Integration methods
Embedding
Oracle has provided an extension activity for BPEL which allows Java embedding. By using this activity, Java code can be used directly from BPEL. The JsonPath libraries to use in the embedding activity can be put in different locations such as the domain library directory or be deployed as part of the BPEL process. Different classloaders will be involved. To check whether this matters I've tried both locations.
Performance
The Java call happens within the same component engine. Below are measures from when using JSON libraries deployed as part of the BPEL process (in SCA-INF/lib).
 Below are measures from when putting the libraries in the domain library folder.
Below are measures from when putting the libraries in the domain library folder.
 As you can see from the measures, the performance is very comparable. The location where the BPEL process gets it's classes from has no clear measurable consequences for the performance.
As you can see from the measures, the performance is very comparable. The location where the BPEL process gets it's classes from has no clear measurable consequences for the performance.
Re-use potential
When the libraries are placed in the domain lib folder, they can be reused by almost everything deployed on the applications server. This should be considered. When deploying as part of the composite, there is no re-use potential outside the composite except possibly indirectly by calling the composite.
Maintenance considerations
Embedded Java code is difficult to maintain and debug. When deployed as part of a BPEL process, changes to the library require redeployment of the process. When libraries are put in the domain library directory, changes to it, impact all applications using it and might require a restart.
XPath
XPath extension functions can be created and used in BPEL (+ other components) and JDeveloper. This is nicely described on; https://blogs.oracle.com/reynolds/entry/building_your_own_path.
Performance
The custom XPath library is included as part of the SOA infrastructure and does not leave this context. As can be seen, the performance is comparable to the Java embedding method.

Re-use potential
The reuse potential is high. The custom XPath library can be used in different locations/engines, dependent on the descriptor file.
Maintenance considerations
Reuse by different developers in JDeveloper requires minimal local configuration, but this allows GUI support of the custom library. There are no specific changes to BPEL code thus low maintenance overhead. Changing the library on the application server requires a restart of the server.
Spring component
The Java code can be called as a Spring component inside a composite. Here another component within the composite is called. The Java code is executed outside the BPEL engine.
Performance

Re-use potential
The following blog posts links to options with the Spring Framework; https://blogs.oracle.com/rammenon/entry/spring_framework_samples. When deployed inside a composite, reuse is limited to the composite. It is possible to define global Spring beans however, increasing re-use. The code can be created/debugged outside an embedding activity.
Maintenance considerations
The Spring component is relatively new to Oracle SOA Suite so some developers might not know how to work with this option yet. It's maintenance options are better then for the BPEL embedding activity. It is however still deployed as part of a composite.
External webservice
Java code can be externalized completely by for example providing it as a JAX-WS webservice or an EJB.
Performance
Performance is poor compared to the solutions described above. This is most likely due to the overhead of leaving soa-infra and the layers the message needs to pass to be able to be called from BPEL.

Re-use potential
Re-use potential is highest for this option. Even external processes can call the webservice so re-use is not limited to the same application server.
Maintenance considerations
Since the code is completely externalized, this option provides the best maintenance options. It can be developed separately by Java developers and provided to be used by an Oracle SOA developer. Also it can be replaced without requiring a server restart or composite redeploy.
Conclusion
The technical effort required to implement the different methods is comparable. Depending on the usecase/requirements, different options might be relevant. If performance is very important, embedding and XPath expressions might be your best choice. If maintenance and reuse are important, then externalizing the Java code in for example an external webservice might be the better option.
Summary of results

The used code with examples of all embedding options can be downloaded here; https://dl.dropboxusercontent.com/u/6693935/blog/TestJavaEmbedding.zip
In the examples provided in this post, I'm using the JsonPath library (https://code.google.com/p/json-path/) inside a BPEL process. A usecase for this could be that a webclient calls the BPEL process with a JSON message and BPEL needs to extract fields from that message.
The Java code to execute, is the following;
package ms.testapp;
import com.jayway.jsonpath.JsonPath;
public class JsonPathUtils {
public String ExecuteJsonPath(String jsonstring, String jsonpath) {
String result = JsonPath.read(jsonstring, jsonpath).toString();
return result;
}
public JsonPathUtils() {
super();
}
}
Of course small changes were necessary for the specific integration methods. I provided code samples at the end of this post for every method.
Integration methods
Embedding
Oracle has provided an extension activity for BPEL which allows Java embedding. By using this activity, Java code can be used directly from BPEL. The JsonPath libraries to use in the embedding activity can be put in different locations such as the domain library directory or be deployed as part of the BPEL process. Different classloaders will be involved. To check whether this matters I've tried both locations.
Performance
The Java call happens within the same component engine. Below are measures from when using JSON libraries deployed as part of the BPEL process (in SCA-INF/lib).


Re-use potential
When the libraries are placed in the domain lib folder, they can be reused by almost everything deployed on the applications server. This should be considered. When deploying as part of the composite, there is no re-use potential outside the composite except possibly indirectly by calling the composite.
Maintenance considerations
Embedded Java code is difficult to maintain and debug. When deployed as part of a BPEL process, changes to the library require redeployment of the process. When libraries are put in the domain library directory, changes to it, impact all applications using it and might require a restart.
XPath
XPath extension functions can be created and used in BPEL (+ other components) and JDeveloper. This is nicely described on; https://blogs.oracle.com/reynolds/entry/building_your_own_path.
Performance
The custom XPath library is included as part of the SOA infrastructure and does not leave this context. As can be seen, the performance is comparable to the Java embedding method.

Re-use potential
The reuse potential is high. The custom XPath library can be used in different locations/engines, dependent on the descriptor file.
Maintenance considerations
Reuse by different developers in JDeveloper requires minimal local configuration, but this allows GUI support of the custom library. There are no specific changes to BPEL code thus low maintenance overhead. Changing the library on the application server requires a restart of the server.
Spring component
The Java code can be called as a Spring component inside a composite. Here another component within the composite is called. The Java code is executed outside the BPEL engine.
Performance

Re-use potential
The following blog posts links to options with the Spring Framework; https://blogs.oracle.com/rammenon/entry/spring_framework_samples. When deployed inside a composite, reuse is limited to the composite. It is possible to define global Spring beans however, increasing re-use. The code can be created/debugged outside an embedding activity.
Maintenance considerations
The Spring component is relatively new to Oracle SOA Suite so some developers might not know how to work with this option yet. It's maintenance options are better then for the BPEL embedding activity. It is however still deployed as part of a composite.
External webservice
Java code can be externalized completely by for example providing it as a JAX-WS webservice or an EJB.
Performance
Performance is poor compared to the solutions described above. This is most likely due to the overhead of leaving soa-infra and the layers the message needs to pass to be able to be called from BPEL.

Re-use potential
Re-use potential is highest for this option. Even external processes can call the webservice so re-use is not limited to the same application server.
Maintenance considerations
Since the code is completely externalized, this option provides the best maintenance options. It can be developed separately by Java developers and provided to be used by an Oracle SOA developer. Also it can be replaced without requiring a server restart or composite redeploy.
Conclusion
The technical effort required to implement the different methods is comparable. Depending on the usecase/requirements, different options might be relevant. If performance is very important, embedding and XPath expressions might be your best choice. If maintenance and reuse are important, then externalizing the Java code in for example an external webservice might be the better option.
Summary of results
This is of course a personal opinion.
Friday, June 29, 2012
FileAdapter pipelines and valves for pre- and postprocessing
Introduction
In a previous post I've written about using the Spring component in order to process files, which the FileAdapter cannot process (http://javaoraclesoa.blogspot.nl/2012/03/file-processing-using-spring-component.html). Another alternative for this is using a pre-processing step in the FileAdapter by implementing pipelines and valves. This is described on; http://docs.oracle.com/cd/E17904_01/integration.1111/e10231/adptr_file.htm#BABJCJEH
I of course had to try this out in order to make an informed judgement when asked about the preferred method for a specific use case. I've used the example provided by Oracle in their documentation; encrypting and decrypting files. I created two processes. One for encrypting and one for decrypting.
The below image from the Oracle documentation shows how the mechanism of using pipelines and valves works. The FileAdapter can be configured (a property in the JCA file) to call a pipeline (described in an XML file). The pipeline consists of references to valve Java classes and some configuration properties. Valves can be chained. It is also possible to do some debatching in the form of a so-called Re-Entrant Valve. This can for example be used if the FileAdapter picks up a ZIP file and the separate files need to be offered to the subsequent processing steps one at a time. I would suggest reading the documentation on this.
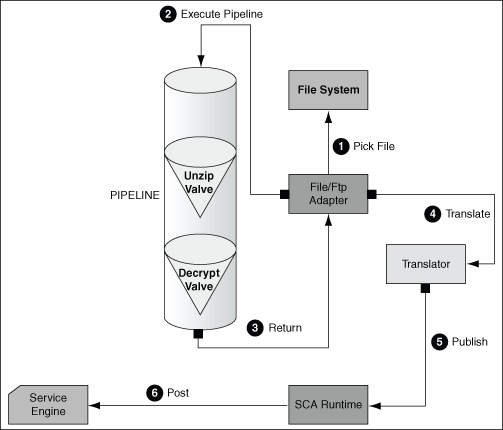
In this post I will describe my tryout of the FileAdapter pipelines and valves and the problems I've encountered. I will describe the steps which I have done and provide a sample project for download. In order to describe the steps, I will repeat some of the actions described in the manual.
Implementation
Java
First you need to create a Java project containing the code for the (custom) valves. You need to include the libraries as shown in the screenshot below. I needed to add the bpm-infra.jar. It is located in; <JDev home>\soa\modules\oracle.soa.fabric_11.1.1

I noticed the SimpleEncryptValve example code provided by Oracle missed some code. In the sample projects which are for download at the end of this post, I've corrected this.
When you've created the valves package and added the Java code examples, you can create a new JAR deployment profile in order to package the files.

When you have the JAR, you can put it in; $MW_HOME/user_projects/domains/soainfra/lib on the application server.
In the Oracle supplied example, the Cipher key needs to be 8 bytes long, else (in case you for example use 9 bytes) the following error will occur;
faultName: {{http://schemas.oracle.com/bpel/extension}remoteFault} messageType: {{http://schemas.oracle.com/bpel/extension}RuntimeFaultMessage} parts: {{ summary=<summary>Exception occured when binding was invoked. Exception occured during invocation of JCA binding: "JCA Binding execute of Reference operation 'Write' failed due to: Unable to execute outbound interaction. Unable to execute outbound interaction. Unable to execute outbound interaction. Please make sure that the file outbound interaction has been configured correctly. ". The invoked JCA adapter raised a resource exception. Please examine the above error message carefully to determine a resolution. </summary> ,detail=<detail>Invalid key length: 9 bytes</detail> ,code=<code>null</code>}
A nice feature which can be used to obtain the filename and path from the context inside a valve can be found here; https://forums.oracle.com/forums/thread.jspa?messageID=10410343. inputStreamContext.getMessageOriginReference() returns a String which contains filename/path.
SCA
In order to configure the FileAdapter to call the created valves, there are two options. You can specify them comma separated as the jca FileAdapter property PipelineValves. For example;
<property name="PipelineValves" value="valves.SimpleUnzipValve,valves.SimpleDecryptValve"/>
This is however not very flexable; it is not possible to specify additional parameters. The second option is to create a pipeline definition and refer to that definition with the property PipelineFile. For example;
<property name="PipelineFile" value="simpleencryptpipeline.xml"/>
Pipeline definition: simpleencryptpipeline.xml;
<?xml version="1.0"?>
<pipeline xmlns="http://www.oracle.com/adapter/pipeline">
<valves>
<valve>valves.SimpleEncryptValve</valve>
</valves>
</pipeline>
If a valve is reentrant (can be called more then once returning a new InputStreamContext when for example unzipping multiple files), you can specify that as follows;
<?xml version="1.0"?>
<pipeline xmlns="http://www.oracle.com/adapter/pipeline">
<valves>
<valve reentrant="true">valves.ReentrantUnzipValve</valve>
<valve> valves.SimpleDecryptValve </valve>
</valves>
</pipeline>
My tryout did not result in correct encoding and decoding back to the original file. After having encoded the file and offering it to the decoder, the result differs from the original file. Because the decoded result is different from the encoded file I offered to the process and I did not do any further processing on the file I read, one can conclude that the valve did get executed, however the logic in the valve is incorrect
Since I'm not interested in diving deeply into security algorithms (that's a different although related specialty), I've not spend more time on finding out what the actual problem is. Suggestions are welcome ;)
Conclusion
Using pipelines and valves allows pre- and post processing of files. This allows the FileAdapter to be used in more situations, which can limit the requirement to build certain functionality from scratch in (for example) a Spring component when the input/output files differ slightly from what the FileAdapter can handle.
Valves and pipelines also have several other nice options for usage as for example listed on; http://technology.amis.nl/2011/10/24/soa-suite-file-adapter-pre-and-post-processing-using-valves-and-pipelines/
Valves however when placed on the application server classpath and not deployed as part of a composite, become available to all deployed composites. This limits the flexibility; replacing the valves will impact all composites using them.
If application specific libraries are required, putting Jar's in a composite and use them in a Spring component, can be preferable to making these libraries available to all applications by implementing them in valves put on the application server.
However, debugging and error handling of pipelines/valves is quite nice. Error messages are clear and you can use properties as defined in the composite in valves by using methods like; getPipeline().getPipelineContext().getProperty("myCipherKey"). These properties can be maintained at runtime; http://beatechnologies.wordpress.com/tag/persist-the-values-of-preferences-in-bpel/. When using Spring components, you don't have the SCA context available without feeding it as parameters to the component (maybe it is available but I did not spend enough time looking for it. Please correct me if I'm wrong on this).
You can download my sample projects here
In a previous post I've written about using the Spring component in order to process files, which the FileAdapter cannot process (http://javaoraclesoa.blogspot.nl/2012/03/file-processing-using-spring-component.html). Another alternative for this is using a pre-processing step in the FileAdapter by implementing pipelines and valves. This is described on; http://docs.oracle.com/cd/E17904_01/integration.1111/e10231/adptr_file.htm#BABJCJEH
I of course had to try this out in order to make an informed judgement when asked about the preferred method for a specific use case. I've used the example provided by Oracle in their documentation; encrypting and decrypting files. I created two processes. One for encrypting and one for decrypting.
The below image from the Oracle documentation shows how the mechanism of using pipelines and valves works. The FileAdapter can be configured (a property in the JCA file) to call a pipeline (described in an XML file). The pipeline consists of references to valve Java classes and some configuration properties. Valves can be chained. It is also possible to do some debatching in the form of a so-called Re-Entrant Valve. This can for example be used if the FileAdapter picks up a ZIP file and the separate files need to be offered to the subsequent processing steps one at a time. I would suggest reading the documentation on this.

In this post I will describe my tryout of the FileAdapter pipelines and valves and the problems I've encountered. I will describe the steps which I have done and provide a sample project for download. In order to describe the steps, I will repeat some of the actions described in the manual.
Implementation
Java
First you need to create a Java project containing the code for the (custom) valves. You need to include the libraries as shown in the screenshot below. I needed to add the bpm-infra.jar. It is located in; <JDev home>\soa\modules\oracle.soa.fabric_11.1.1

I noticed the SimpleEncryptValve example code provided by Oracle missed some code. In the sample projects which are for download at the end of this post, I've corrected this.
When you've created the valves package and added the Java code examples, you can create a new JAR deployment profile in order to package the files.

When you have the JAR, you can put it in; $MW_HOME/user_projects/domains/soainfra/lib on the application server.
In the Oracle supplied example, the Cipher key needs to be 8 bytes long, else (in case you for example use 9 bytes) the following error will occur;
faultName: {{http://schemas.oracle.com/bpel/extension}remoteFault} messageType: {{http://schemas.oracle.com/bpel/extension}RuntimeFaultMessage} parts: {{ summary=<summary>Exception occured when binding was invoked. Exception occured during invocation of JCA binding: "JCA Binding execute of Reference operation 'Write' failed due to: Unable to execute outbound interaction. Unable to execute outbound interaction. Unable to execute outbound interaction. Please make sure that the file outbound interaction has been configured correctly. ". The invoked JCA adapter raised a resource exception. Please examine the above error message carefully to determine a resolution. </summary> ,detail=<detail>Invalid key length: 9 bytes</detail> ,code=<code>null</code>}
A nice feature which can be used to obtain the filename and path from the context inside a valve can be found here; https://forums.oracle.com/forums/thread.jspa?messageID=10410343. inputStreamContext.getMessageOriginReference() returns a String which contains filename/path.
SCA
In order to configure the FileAdapter to call the created valves, there are two options. You can specify them comma separated as the jca FileAdapter property PipelineValves. For example;
<property name="PipelineValves" value="valves.SimpleUnzipValve,valves.SimpleDecryptValve"/>
This is however not very flexable; it is not possible to specify additional parameters. The second option is to create a pipeline definition and refer to that definition with the property PipelineFile. For example;
<property name="PipelineFile" value="simpleencryptpipeline.xml"/>
Pipeline definition: simpleencryptpipeline.xml;
<?xml version="1.0"?>
<pipeline xmlns="http://www.oracle.com/adapter/pipeline">
<valves>
<valve>valves.SimpleEncryptValve</valve>
</valves>
</pipeline>
If a valve is reentrant (can be called more then once returning a new InputStreamContext when for example unzipping multiple files), you can specify that as follows;
<?xml version="1.0"?>
<pipeline xmlns="http://www.oracle.com/adapter/pipeline">
<valves>
<valve reentrant="true">valves.ReentrantUnzipValve</valve>
<valve> valves.SimpleDecryptValve </valve>
</valves>
</pipeline>
My tryout did not result in correct encoding and decoding back to the original file. After having encoded the file and offering it to the decoder, the result differs from the original file. Because the decoded result is different from the encoded file I offered to the process and I did not do any further processing on the file I read, one can conclude that the valve did get executed, however the logic in the valve is incorrect
Since I'm not interested in diving deeply into security algorithms (that's a different although related specialty), I've not spend more time on finding out what the actual problem is. Suggestions are welcome ;)
Conclusion
Using pipelines and valves allows pre- and post processing of files. This allows the FileAdapter to be used in more situations, which can limit the requirement to build certain functionality from scratch in (for example) a Spring component when the input/output files differ slightly from what the FileAdapter can handle.
Valves and pipelines also have several other nice options for usage as for example listed on; http://technology.amis.nl/2011/10/24/soa-suite-file-adapter-pre-and-post-processing-using-valves-and-pipelines/
Valves however when placed on the application server classpath and not deployed as part of a composite, become available to all deployed composites. This limits the flexibility; replacing the valves will impact all composites using them.
If application specific libraries are required, putting Jar's in a composite and use them in a Spring component, can be preferable to making these libraries available to all applications by implementing them in valves put on the application server.
However, debugging and error handling of pipelines/valves is quite nice. Error messages are clear and you can use properties as defined in the composite in valves by using methods like; getPipeline().getPipelineContext().getProperty("myCipherKey"). These properties can be maintained at runtime; http://beatechnologies.wordpress.com/tag/persist-the-values-of-preferences-in-bpel/. When using Spring components, you don't have the SCA context available without feeding it as parameters to the component (maybe it is available but I did not spend enough time looking for it. Please correct me if I'm wrong on this).
You can download my sample projects here
Tuesday, March 27, 2012
File processing using a Spring component
Introduction
The Oracle SOA Suite 11g FileAdapter provides (among other things) functionality to read a variety of text file formats such as CSV and transform them into XML. This makes it easier to use them in for example BPEL. Usually the FileAdapter provides enough functionality to correctly parse files. Sometimes however, this is not possible. An example of such a file;
h1;h2;h3;h4
A;B;C;D
E;F;G;H
Total: 2
h1 to h4 are header fields. The second and third line are the records and the last line indicates how many records are present in the file.
The last line cannot be excluded from parsing by the FileAdapter and will lead to errors. As a workaround and to provide some flexibility in file parsing, the following solution can be implemented. Keep in mind that this solution will cause problems for large files since the file will in memory be converted to XML.
Read the file as opaque using the FileAdapter. Create a Java class which has a public method with a byte array as input parameter and some parsing parameters. Wrap the Java class as a Spring component. Then you can use the component in a BPEL process as JDeveloper will generate XSD's/WSDL's for the Spring component for you.
Implementation
FileAdapter
In BPEL define a file adapter and select not to use a schema;


Java class parsefile
A Java class does the parsing. You can of course expand this example. Currently empty lines are also processed as entries, which might not be what you want. This class is also specific for the example given in the introduction (but is flexible enough for related file formats). I have chosen to return an ArrayList of ArrayLists. The first (outer) ArrayList contains the records of the file and the inner ArrayList contains the items in the record separated on a separator regular expression. The header lines can be ignored and you can specify to skip lines starting with a specific string. If you want to be able to skip multiple strings (in order to make a selection in the file of lines to process), you can change the type of the last parameter of the parse function to ArrayList and alter the code to loop over that.
Create the following Java class;


package nl.smeets.myfilereader;
import java.io.BufferedReader;
import java.io.ByteArrayInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
public class parsefile {
public parsefile() {
super();
}
public ArrayList<ArrayList<String>> parse(byte[] bytes_in,
String separator,
Integer ignorefirstlines,
String ignoreStartsWith) {
ArrayList<ArrayList<String>> l_retval =
new ArrayList<ArrayList<String>>();
ByteArrayInputStream ba_in = new ByteArrayInputStream(bytes_in);
BufferedReader br_in =
new BufferedReader(new InputStreamReader(ba_in));
Integer linecounter = 0;
String line = null;
try {
while ((line = br_in.readLine()) != null) {
if (!line.startsWith(ignoreStartsWith) &&
linecounter >= ignorefirstlines) {
l_retval.add(parseLine(line, separator));
}
linecounter++;
}
} catch (FileNotFoundException ex) {
ex.printStackTrace();
} catch (IOException ex) {
ex.printStackTrace();
} finally {
//Close the BufferedReader
try {
if (br_in != null)
br_in.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
return l_retval;
}
ArrayList<String> parseLine(String input, String separator) {
ArrayList<String> retval = new ArrayList<String>();
String[] splitVals = input.split(separator);
for (String addVal : splitVals) {
retval.add(addVal);
}
return retval;
}
public static void main(String[] args) {
//test; skips first line and all lines starting with Total. uses ; as separator
//parsefile parsefile = new parsefile();
//System.out.println(parsefile.parse("h1;h2;h3;h4\ne1;f1;g1;h1\ne2;f2;g2;h2\nTotal: 1".getBytes(), ";", 1, "Total"));
}
}
Extract interface
Right-click the Java file, Refactor, Extract interface

Spring bean
Use the wizard to create a Spring bean and define it as follows;

<?xml version="1.0" encoding="windows-1252" ?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:util="http://www.springframework.org/schema/util"
xmlns:jee="http://www.springframework.org/schema/jee"
xmlns:lang="http://www.springframework.org/schema/lang"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:sca="http://xmlns.oracle.com/weblogic/weblogic-sca"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-2.5.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee-2.5.xsd http://www.springframework.org/schema/lang http://www.springframework.org/schema/lang/spring-lang-2.5.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd http://www.springframework.org/schema/tool http://www.springframework.org/schema/tool/spring-tool-2.5.xsd http://xmlns.oracle.com/weblogic/weblogic-sca META-INF/weblogic-sca.xsd">
<bean name="ParseFileBean" class="nl.smeets.myfilereader.parsefile"/>
<sca:service name="ParseFileBeanService" target="ParseFileBean" type="nl.smeets.myfilereader.Iparsefile"/>
</beans>
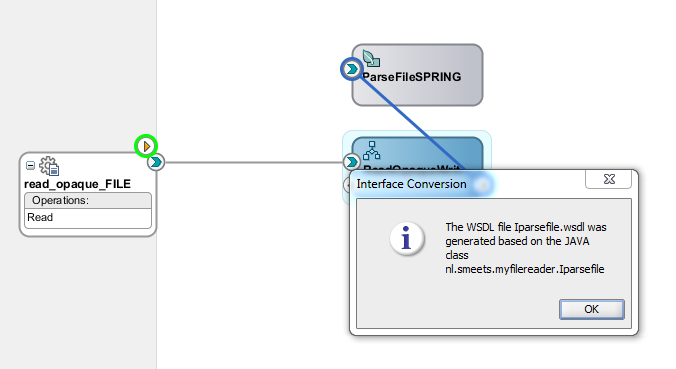
First make sure the Java interface and class are compiled to avoid errors such as the one below;

Now you can use the composite editor to expose the Spring bean or use it in a BPEL process.

BPEL
Use BPEL to bring it all together. In BPEL you can assign the parameters of the parsing Java method. In this example I've hardcoded them in the process but of course you can also use BPEL preferences (described in a previous post; http://javaoraclesoa.blogspot.com/2012/02/changing-properties-of-bpel-process-at.html) which can be defined in the composite.xml file and modified at runtime so if the format of the file changes, you don't have to redeploy the BPEL process. Don't forget to update the configuration plan supplied to reflect your local environment. *.txt files from (logical path) READ_FILE_DIR are read and xml files are written as output to logical path WRITE_FILE_DIR.
Input;
h1;h2;h3;h4
A;B;C;D
E;F;G;H
Total: 2
Output;
<?xml version="1.0" encoding="UTF-8" ?>
<parseResponse xmlns="http://myfilereader.smeets.nl/">
<return xmlns:ns0="http://myfilereader.smeets.nl/types" xmlns="">
<item>A</item>
<item>B</item>
<item>C</item>
<item>D</item>
</return>
<return xmlns:ns0="http://myfilereader.smeets.nl/types" xmlns="">
<item>E</item>
<item>F</item>
<item>G</item>
<item>H</item>
</return>
</parseResponse>
You can download the entire example here; https://www.dropbox.com/s/ytgwjz7zjlvscmj/DemoReadFile.zip?dl=0
The Oracle SOA Suite 11g FileAdapter provides (among other things) functionality to read a variety of text file formats such as CSV and transform them into XML. This makes it easier to use them in for example BPEL. Usually the FileAdapter provides enough functionality to correctly parse files. Sometimes however, this is not possible. An example of such a file;
h1;h2;h3;h4
A;B;C;D
E;F;G;H
Total: 2
h1 to h4 are header fields. The second and third line are the records and the last line indicates how many records are present in the file.
The last line cannot be excluded from parsing by the FileAdapter and will lead to errors. As a workaround and to provide some flexibility in file parsing, the following solution can be implemented. Keep in mind that this solution will cause problems for large files since the file will in memory be converted to XML.
Read the file as opaque using the FileAdapter. Create a Java class which has a public method with a byte array as input parameter and some parsing parameters. Wrap the Java class as a Spring component. Then you can use the component in a BPEL process as JDeveloper will generate XSD's/WSDL's for the Spring component for you.
Implementation
FileAdapter
In BPEL define a file adapter and select not to use a schema;


Java class parsefile
A Java class does the parsing. You can of course expand this example. Currently empty lines are also processed as entries, which might not be what you want. This class is also specific for the example given in the introduction (but is flexible enough for related file formats). I have chosen to return an ArrayList of ArrayLists. The first (outer) ArrayList contains the records of the file and the inner ArrayList contains the items in the record separated on a separator regular expression. The header lines can be ignored and you can specify to skip lines starting with a specific string. If you want to be able to skip multiple strings (in order to make a selection in the file of lines to process), you can change the type of the last parameter of the parse function to ArrayList and alter the code to loop over that.
Create the following Java class;


package nl.smeets.myfilereader;
import java.io.BufferedReader;
import java.io.ByteArrayInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
public class parsefile {
public parsefile() {
super();
}
public ArrayList<ArrayList<String>> parse(byte[] bytes_in,
String separator,
Integer ignorefirstlines,
String ignoreStartsWith) {
ArrayList<ArrayList<String>> l_retval =
new ArrayList<ArrayList<String>>();
ByteArrayInputStream ba_in = new ByteArrayInputStream(bytes_in);
BufferedReader br_in =
new BufferedReader(new InputStreamReader(ba_in));
Integer linecounter = 0;
String line = null;
try {
while ((line = br_in.readLine()) != null) {
if (!line.startsWith(ignoreStartsWith) &&
linecounter >= ignorefirstlines) {
l_retval.add(parseLine(line, separator));
}
linecounter++;
}
} catch (FileNotFoundException ex) {
ex.printStackTrace();
} catch (IOException ex) {
ex.printStackTrace();
} finally {
//Close the BufferedReader
try {
if (br_in != null)
br_in.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
return l_retval;
}
ArrayList<String> parseLine(String input, String separator) {
ArrayList<String> retval = new ArrayList<String>();
String[] splitVals = input.split(separator);
for (String addVal : splitVals) {
retval.add(addVal);
}
return retval;
}
public static void main(String[] args) {
//test; skips first line and all lines starting with Total. uses ; as separator
//parsefile parsefile = new parsefile();
//System.out.println(parsefile.parse("h1;h2;h3;h4\ne1;f1;g1;h1\ne2;f2;g2;h2\nTotal: 1".getBytes(), ";", 1, "Total"));
}
}
Extract interface
Right-click the Java file, Refactor, Extract interface

Spring bean
Use the wizard to create a Spring bean and define it as follows;

<?xml version="1.0" encoding="windows-1252" ?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:util="http://www.springframework.org/schema/util"
xmlns:jee="http://www.springframework.org/schema/jee"
xmlns:lang="http://www.springframework.org/schema/lang"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:sca="http://xmlns.oracle.com/weblogic/weblogic-sca"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-2.5.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee-2.5.xsd http://www.springframework.org/schema/lang http://www.springframework.org/schema/lang/spring-lang-2.5.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd http://www.springframework.org/schema/tool http://www.springframework.org/schema/tool/spring-tool-2.5.xsd http://xmlns.oracle.com/weblogic/weblogic-sca META-INF/weblogic-sca.xsd">
<bean name="ParseFileBean" class="nl.smeets.myfilereader.parsefile"/>
<sca:service name="ParseFileBeanService" target="ParseFileBean" type="nl.smeets.myfilereader.Iparsefile"/>
</beans>
First make sure the Java interface and class are compiled to avoid errors such as the one below;

Now you can use the composite editor to expose the Spring bean or use it in a BPEL process.
BPEL
Use BPEL to bring it all together. In BPEL you can assign the parameters of the parsing Java method. In this example I've hardcoded them in the process but of course you can also use BPEL preferences (described in a previous post; http://javaoraclesoa.blogspot.com/2012/02/changing-properties-of-bpel-process-at.html) which can be defined in the composite.xml file and modified at runtime so if the format of the file changes, you don't have to redeploy the BPEL process. Don't forget to update the configuration plan supplied to reflect your local environment. *.txt files from (logical path) READ_FILE_DIR are read and xml files are written as output to logical path WRITE_FILE_DIR.
Input;
h1;h2;h3;h4
A;B;C;D
E;F;G;H
Total: 2
Output;
<?xml version="1.0" encoding="UTF-8" ?>
<parseResponse xmlns="http://myfilereader.smeets.nl/">
<return xmlns:ns0="http://myfilereader.smeets.nl/types" xmlns="">
<item>A</item>
<item>B</item>
<item>C</item>
<item>D</item>
</return>
<return xmlns:ns0="http://myfilereader.smeets.nl/types" xmlns="">
<item>E</item>
<item>F</item>
<item>G</item>
<item>H</item>
</return>
</parseResponse>
You can download the entire example here; https://www.dropbox.com/s/ytgwjz7zjlvscmj/DemoReadFile.zip?dl=0
Subscribe to:
Posts (Atom)